
Штучний інтелект набирає досить великої популярності останнім часом. При чому на рівні з моделями доступними в хмарі багато користувачів хочуть мати можливість використовувати штучний інтелект локально. Як би там не було, це значно безпечніше, тому що ваші данні нікуди не передаються, а також надійніше, тому що при використанні моделей локально вас не зможуть заблокувати.
Але в такого підходу є і проблеми. Апаратні можливості персональних компьютерів досить обмежені, а тому можливості моделей запущених локально будуть значно менші ніж тих які доступні в хмарі. В цій статті ми розглянемо що це все таке, як це все працює, а також як користуватись Ollama для того щоб запускати моделі штучного інтелекту локально.
Зміст
Необхідні основи
Ollama має досить простий інтерфейс командного рядка, а завантажити і запустити модель можна виконавши декілька команд. Тому почати працювати з цим інструментом досить просто. Реалізовано це все на основі llama.cpp, а моделі AI збережені в форматі GGUF (GPT Generated Unified Format), але нам цим займатись не треба, бо завантаження моделей і конфігурування llama.cpp бере на себе Ollama.
Але для того щоб зрозуміти які моделі можна запускати, а які ні на вашому комп'ютері вам в потрібно знати деякі основи. Якщо дуже спростити, модель штучного інтелекту це величезний набір чисел, розташованих у вигляді певної структури та часто скомбінованих у велику кількість шарів. Кількість цих чисел і є кількість параметрів моделі.
Коли ми виконуємо запит до моделі наш запит конвертується також в числа і ці числа множаться на числа які були в моделі. Звісно це не проста операція і це все відбувається враховуючи структуру зв'язків в моделі та її шари, а потім ми отримуємо результат. Це дуже спрощено, може не зовсім вірно, але відображає в загальному що відбувається.
Оскільки потрібно зробити дуже велику кількість математичних операцій за короткий проміжок часу, для запуску моделей штучного інтелекту використовуються відеокарти. Відеокарти мають багато процесорних ядер які виконують такі задачі значно швидше за процессор. Але для того щоб це запрацювало всі числа моделі та ваш запит повинні поміститись в відео память вашої відеокарти.
Розмір моделі
Для кожної моделі на сайті ollama вказується кількість параметрів та її розмір:
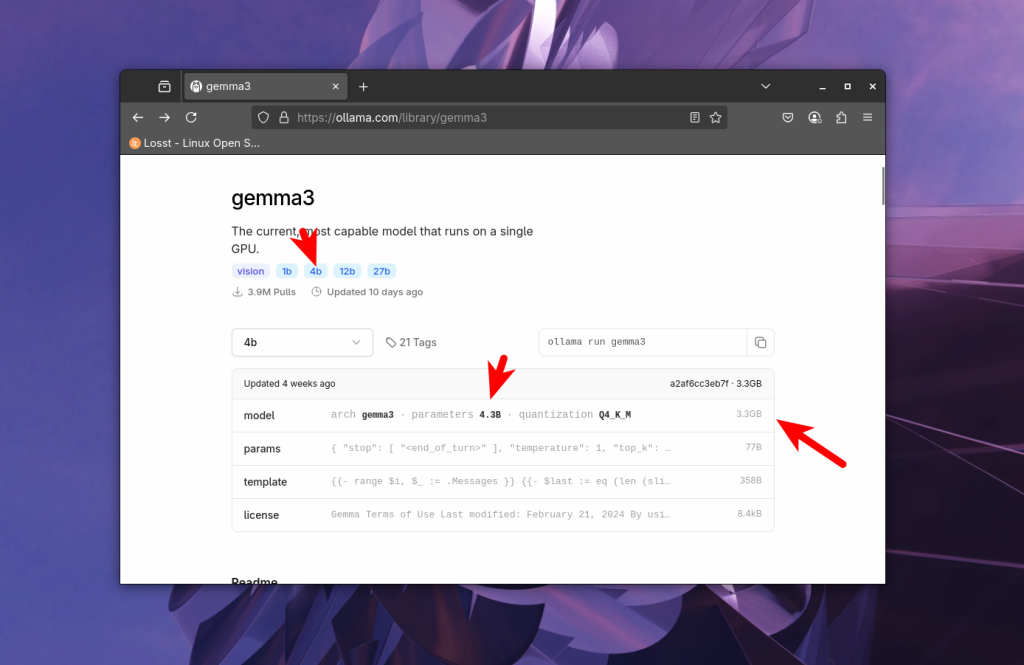
Звісно, можна завантажувати в память відеокарти лише частину моделі, якщо там не вистачає відео пам'яті, а все інше зберігати в оперативній пам'яті. Ollama підтримує це за замовчуванням. Але тоді швидкість взаємодії з моделью падає в десятки разів, тому що компьютеру доводиться часто звертатись до оперативної пам'яті та процессора які не такі швидкі як відеокарта.
Тому розробники моделей намагаються створювати моделі різних розмірів, наприклад 1b, 4b, 12b, 27b. Тут b це мільярд. 12b означає - 12 мільярдів параметрів. Якщо будемо використовувати для зберігання чисел з плаваючою крапкою Float16 (FP16) то в повному розмірі модель на 12 мільярдів параметрів буде займати 12 000 000 000 * 2 байта = 24 гігабайт. Це максимальна точність з якою в ollama доступні моделі. Враховуючи що треба ще десь вмістити данні запиту (контекст) то для запуска такої моделі нам потрібна була б відеокарта більше ніж на 24 гігабайт відеопам'яті.
Квантизація
Відеокарти з великим об'ємом пам'яті коштують досить дорого, тому була придумана квантизація. Точність цифр з яких складається модель зменшується. Так сказати зрізається хвіст, і число яке займало 2 байта починає займати байт, або навіть пів. Це звісно впливає на якість роботи моделі і чим більш квантизована модель - тим гірше вона буде працювати, але тим менше пам'яті буде потребувати. Ось кванти які підтримуються ollama:
- fp16 - максимум, 16 біт, 2 байта
- q8 - 8 біт - пів байта
- q4 - 4 біт - 0,25 байта
Звісно є різні модифікації методів квантизації, які дозволяють покращити якість роботи моделей при тій самій економії пам'яті, але не буду писати тут про них. При виборі моделі на сайті Ollama можна вибрати квант в випадаючому списку:
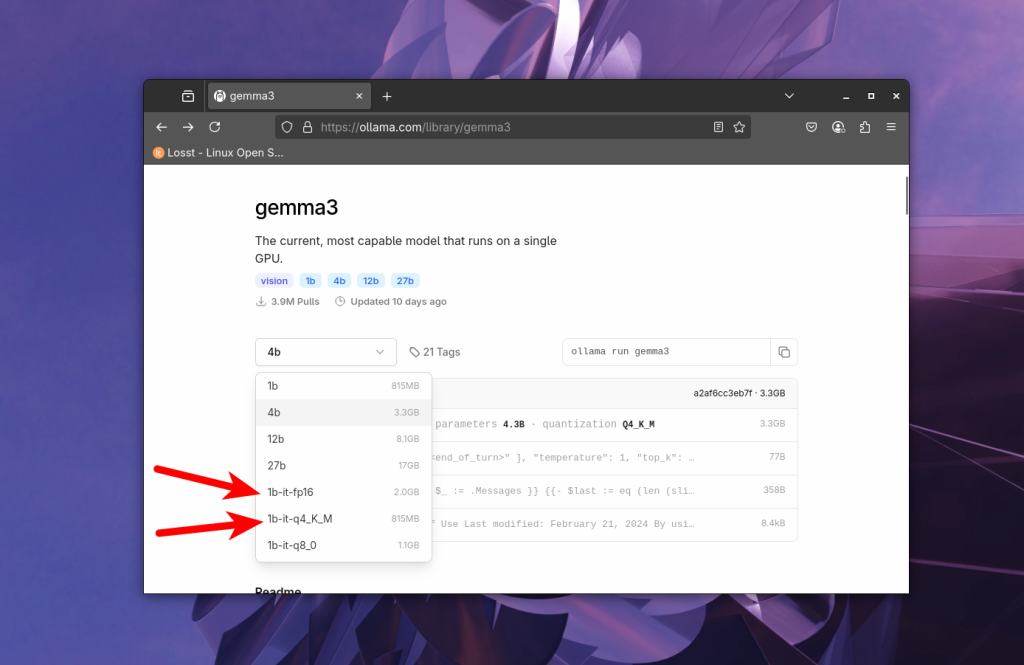
Оптимально брати fp16 для production, а для тестів і всього іншого можна користуватись q4. Наприклад, модель gemma3 на 12 мільярдів параметрів займає 24 Гб, а в Q4 вже 8.8 Гб, а значить її можна буде запустити на RTX 3060, яка має 12 Гб відео пам'яті.
Цього буде достатньо для того щоб зрозуміти яку модель можна завантажувати, а тепер давайте перейдемо безпосередньо до встановлення Ollama.
Встановлення Ollama
Для встановлення Ollama достатньо відкрити сайт https://ollama.com/ та натиснути кнопку Download. Відкриється сторінка, на якій буде команда встановлення для будь-якого дистрибутиву Linux. Фактично це curl команда, яка завантажить та запустить скріпт устаноки ollama в вашій системі. На момент написання статті команда виглядає так:
curl -fsSL https://ollama.com/install.sh | sh
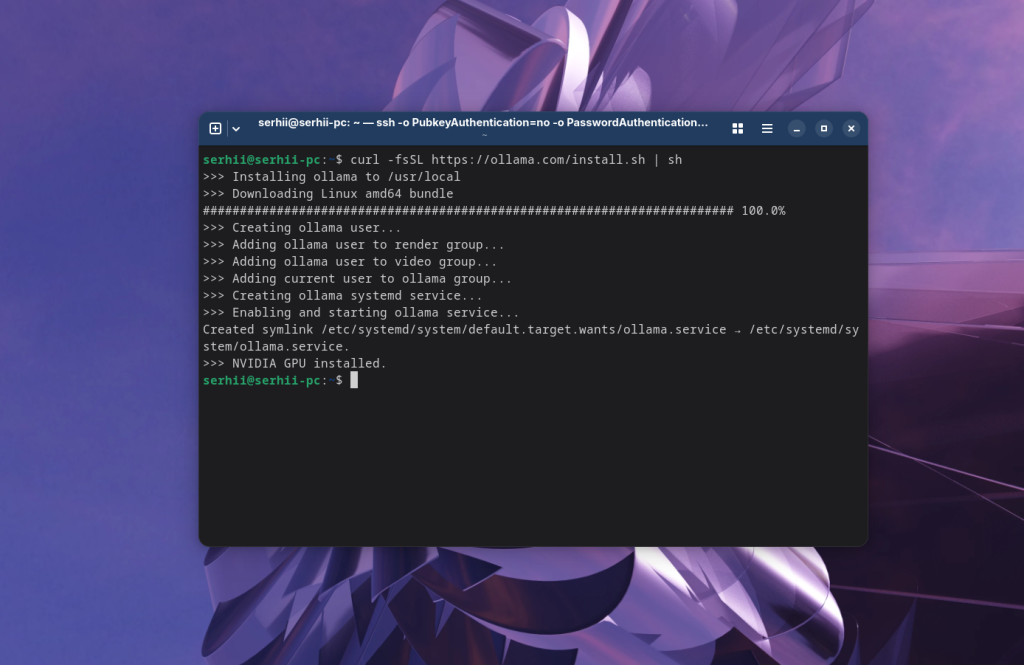
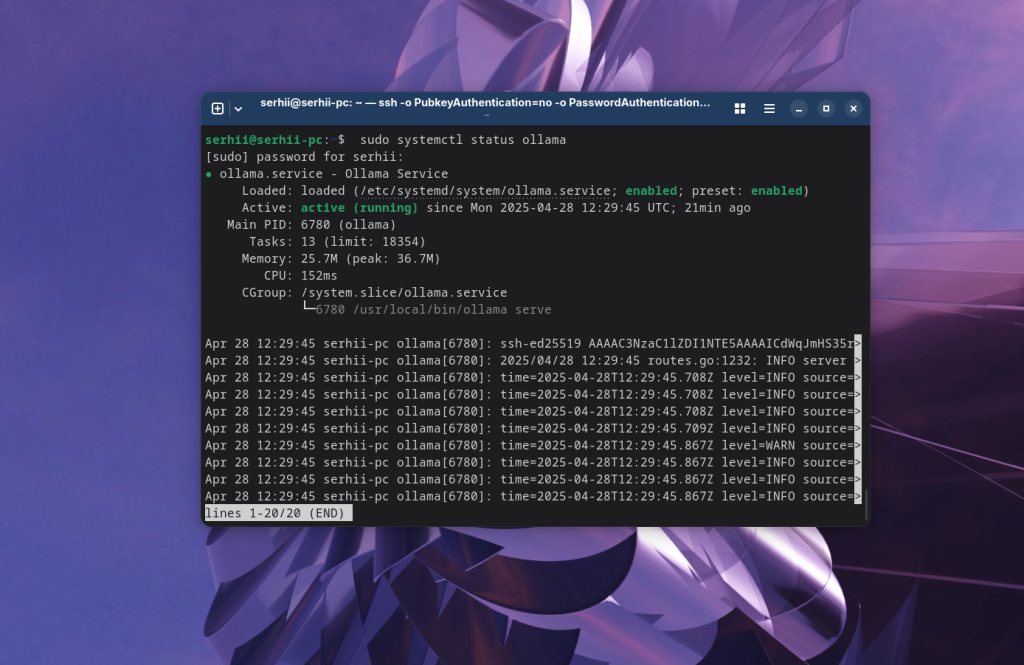
Після завершення виконання сценарію встановлення можна перевірити що служба ollama запущена:
sudo systemctl status ollama
Як користуватись ollama
Після цього можна переходити до використання. Перш за все давайте розглянемо як завантажити модель.
Завантаження моделі
Модель потрібно вибрати на сайті Ollama за допомогою пошуку. Наприклад gemma3:
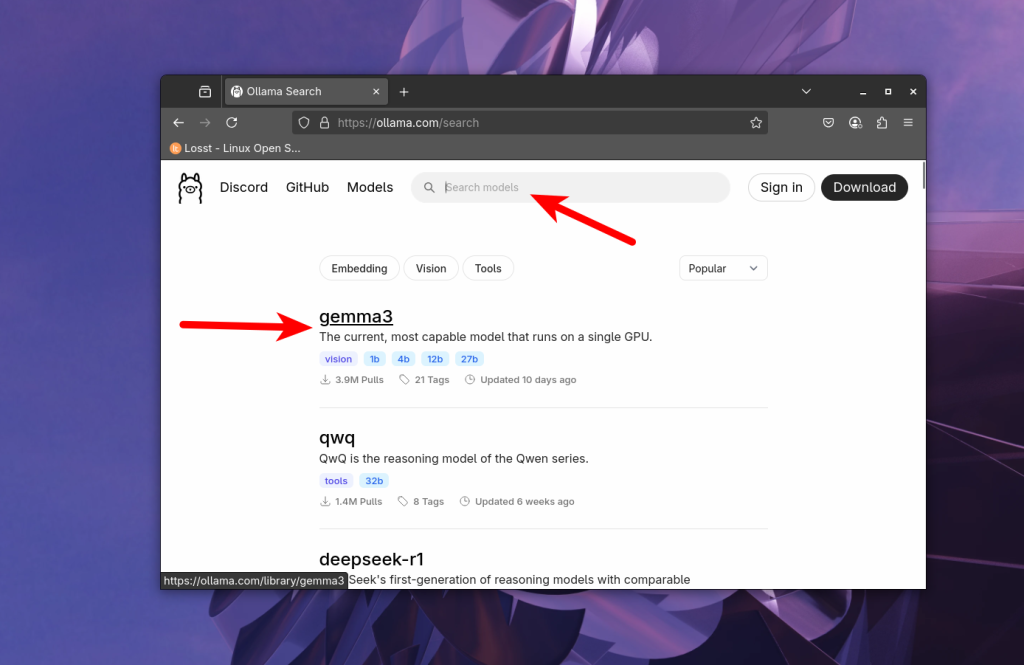
Далі в випадаючому списку вибираємо кількість параметрів та квантизацію моделі, наприклад 12b, за замовчуванням зазвичай використовується квантизація Q4_K_M:
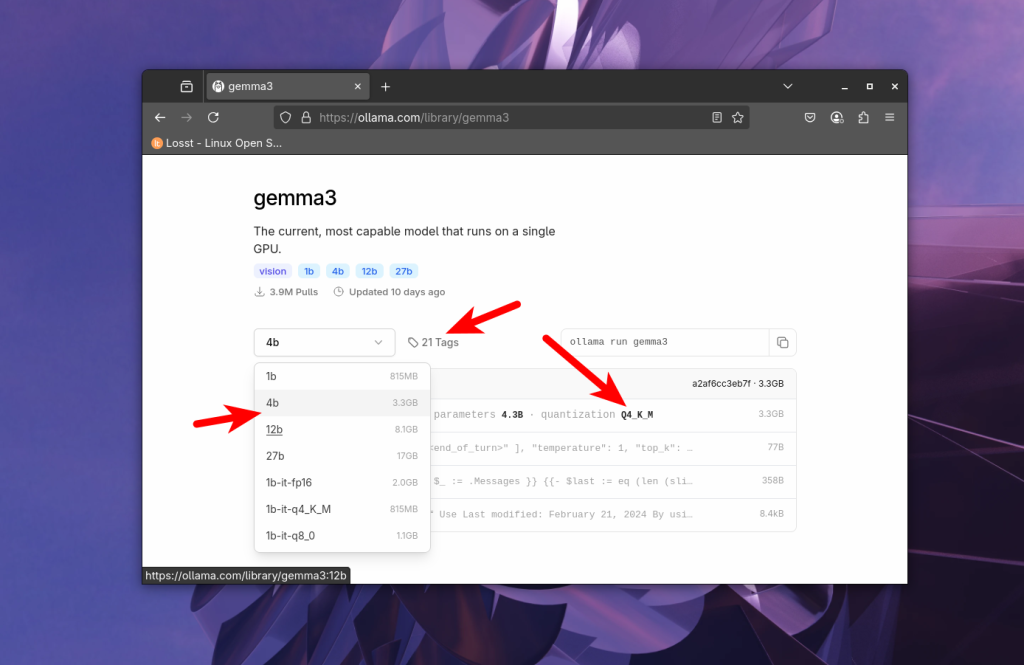
Щоб подивитись всі доступні варіанти треба перейти на вкладку tags:
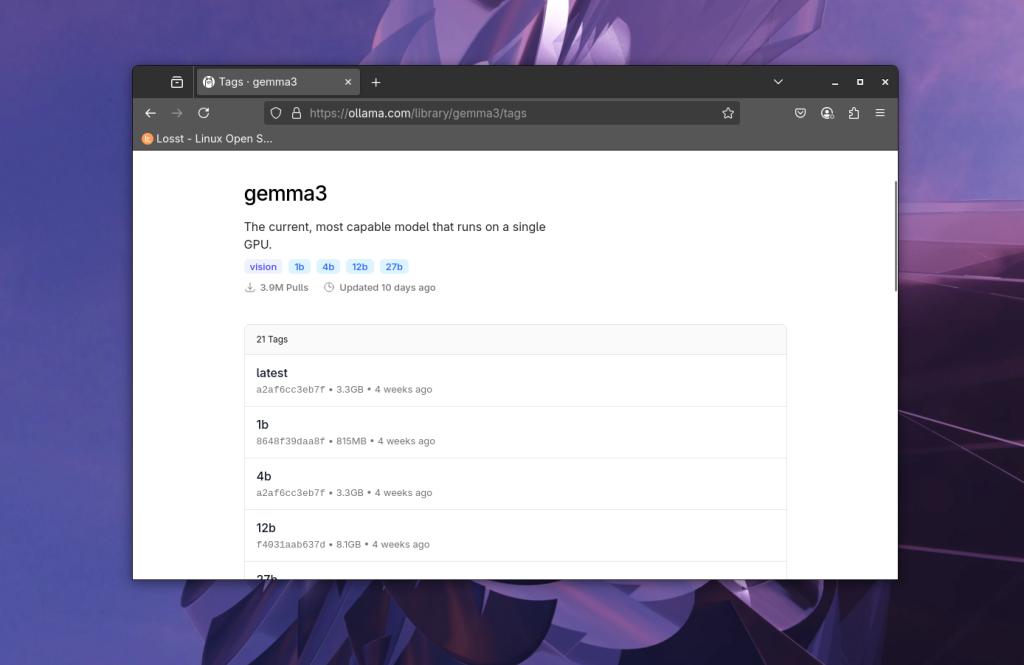
Після вибору моделі, можна побачити інформацію про неї, кількість параметрів, квант, розмір, і т д:
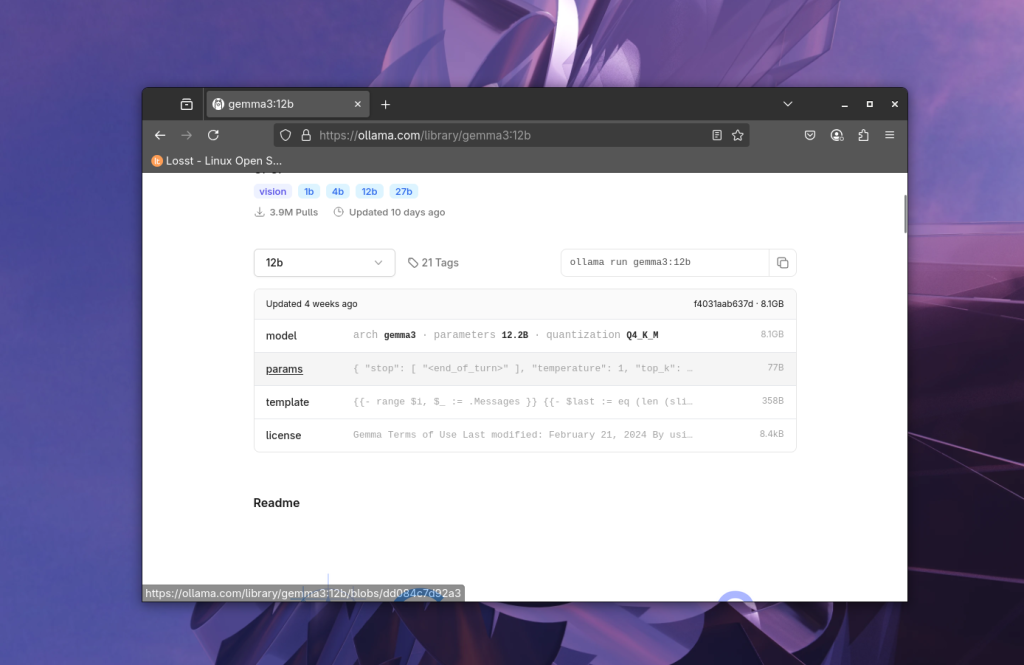
І справа напроти випадаючого списку бачимо команду для запуска моделі в якій є її назва:
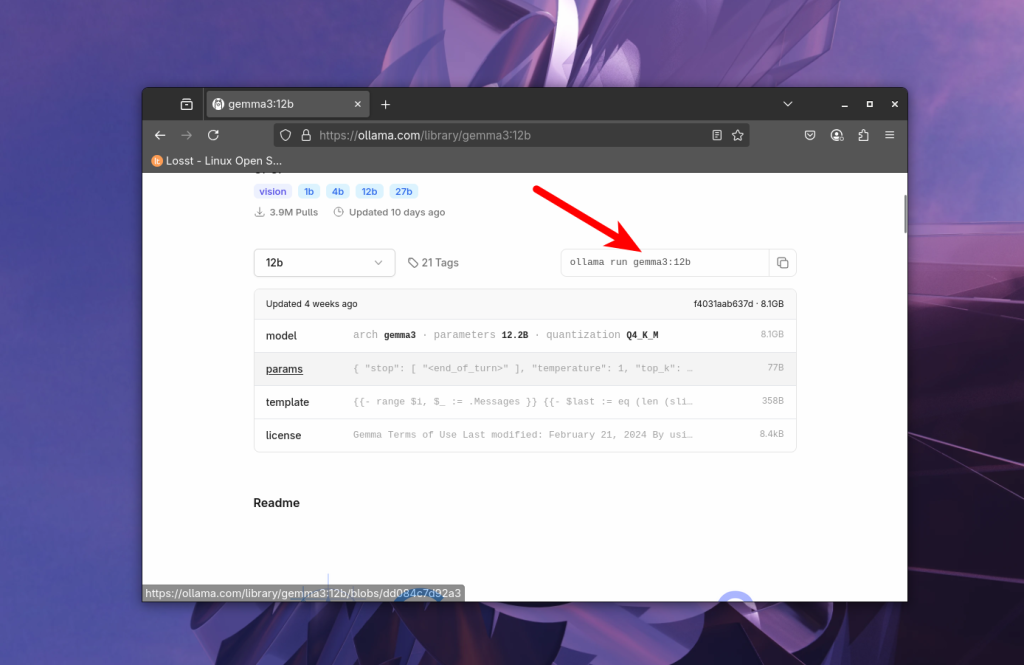
Можна одразу ж виконати запропоновану команду і вона не тільки завантажить її, але і запустить чат з нею в терміналі. Або ж можна просто завантажити модель за допомогою команди pull:
ollama pull gemma3:12b
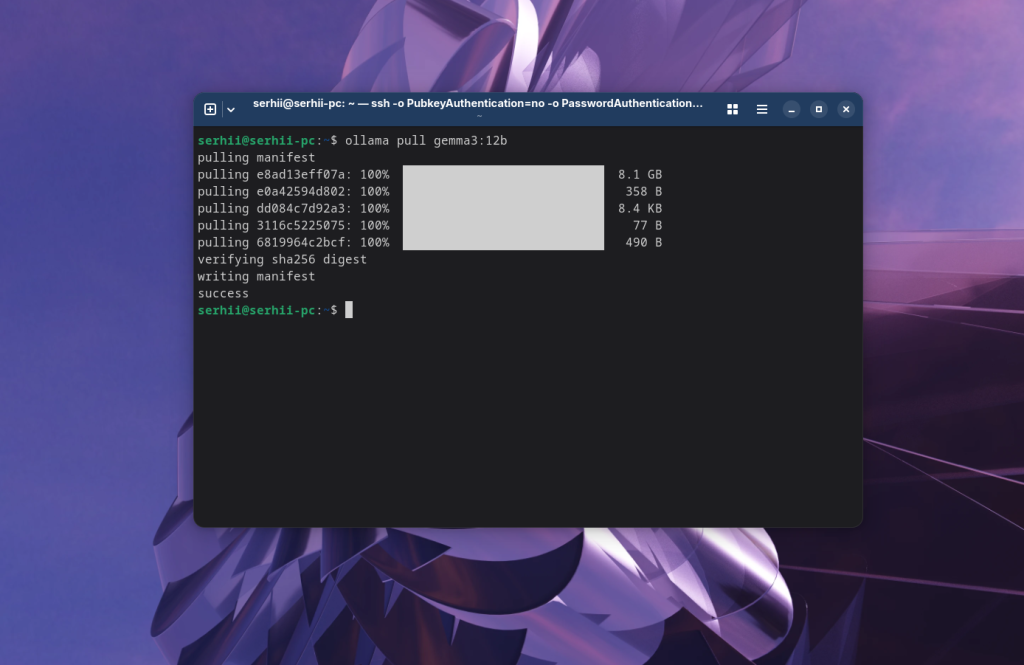
Ще можна повністю вказати квант, який беремо з назви тегу:
ollama pull gemma3:12b-it-q4_K_M
Запуск моделі в терміналі
Після того як модель завантажена можна подивитись список моделей доступних локально за допомогою команди list:
ollama list
Чат з потрібною моделью можна запустити в терміналі за допомогою тієї ж команди run:
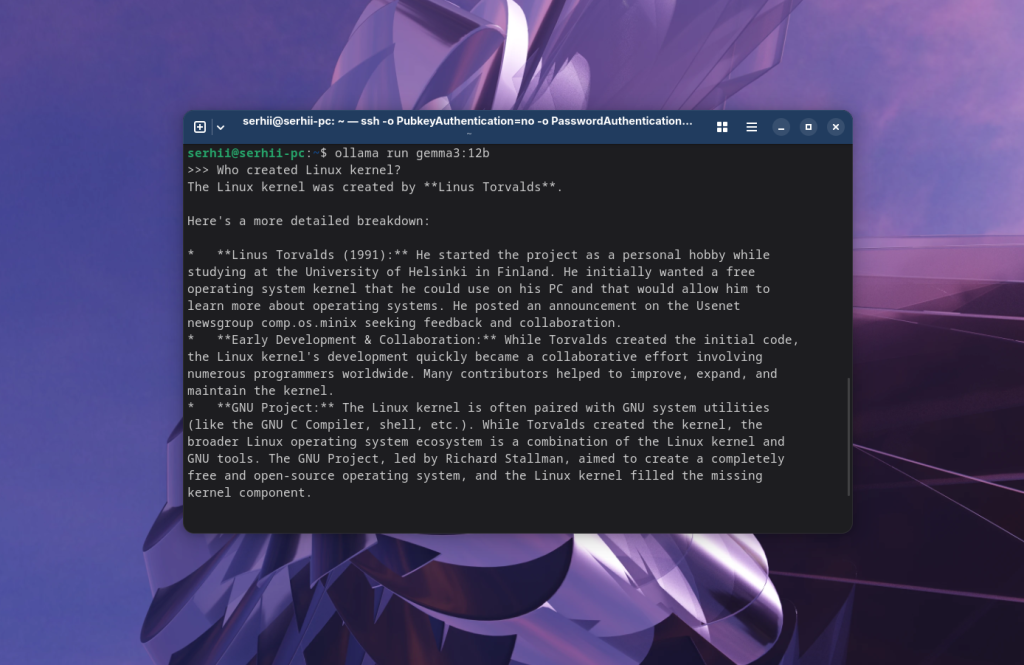
ollama run gemma3:12b
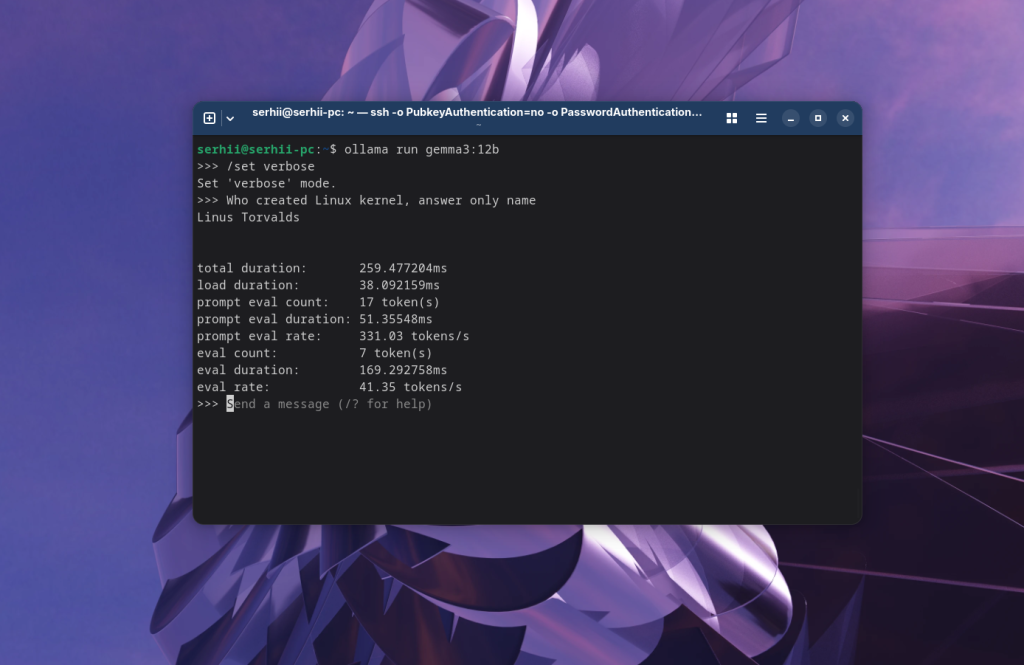
Тут можна задавати запитання для спілкування з моделью. Наприклад: Хто створив ядро Linux:
Ollama може завантажувати моделі як в відеопамять, так і вивантажувати частину шарів в оперативну память, якщо відеопамяті не вистачає. Це все робиться без вашої участі. Якщо ви використовуєте відеокарту Nvidia, то для того щоб перевірити що використовується відеопамять можна скористатись утилитою nvidia_smi:
nvidia_smi
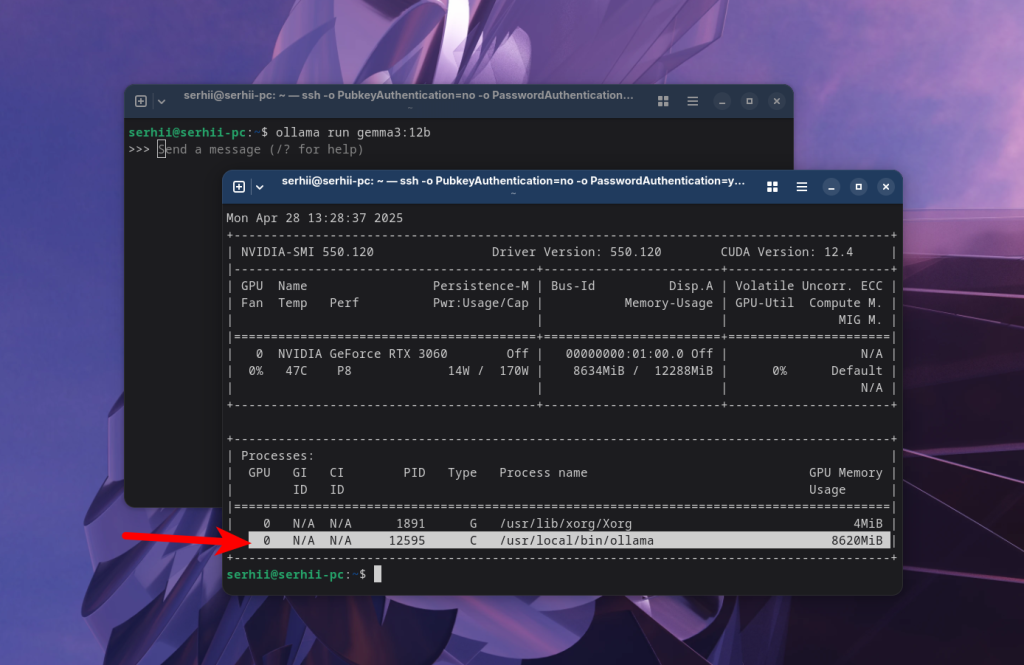
Тут можна бачити що трохи більше ніж 8Гб відеопамяті використовує Ollama, а значить модель завантажена в відеопамять.
Статистика використання
При використанні штучного інтелекту розмір запитів (промптів) які ви передаєте в модель, а також відповідей які отримуєте вимірюється в не в кількості символів, а в кількості токенів. Зазвичай на слово йде десь півтора-два токена. Ви можете увімкнути вивдедення статистики в чаті за допомогою команди:
/set verbose
В статистиці можна побачити не тільки кількість отриманих та згенерованих токенів, а також швидкість генерації, кількість токенів в секунду в полі eval rate:
Системний запит моделі
При взаємодії з моделью штучного інтелекту вказується не тільки поточний запит, але і системний. За замовчуванням в системному запиті зазвичай знаходиться щось типу "you are helpful assistant" або порожньо. Якщо вам потрібно щоб модель виконувала якесь специфічне завдання, ви можете прописати його в системному запиті за допомогою команди /set system. Наприклад:
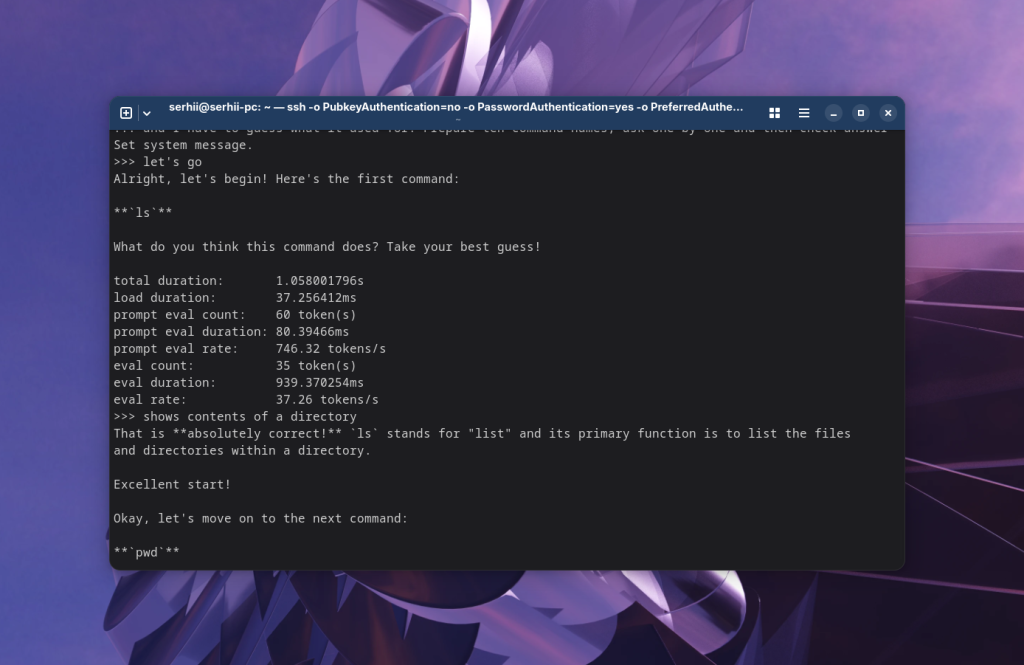
You are my Linux tutor. Today we gonna learn Linux commands. Your task is to name command and I have to guess what it used for. Prepare ten command names, ask one by one and then check answer.
Після цього достатньо написати моделі щось, для того щоб вона почала працювати. Наприклад, let's go:
Подивитись поточний системний запит можна за допомогою команди:
/show system
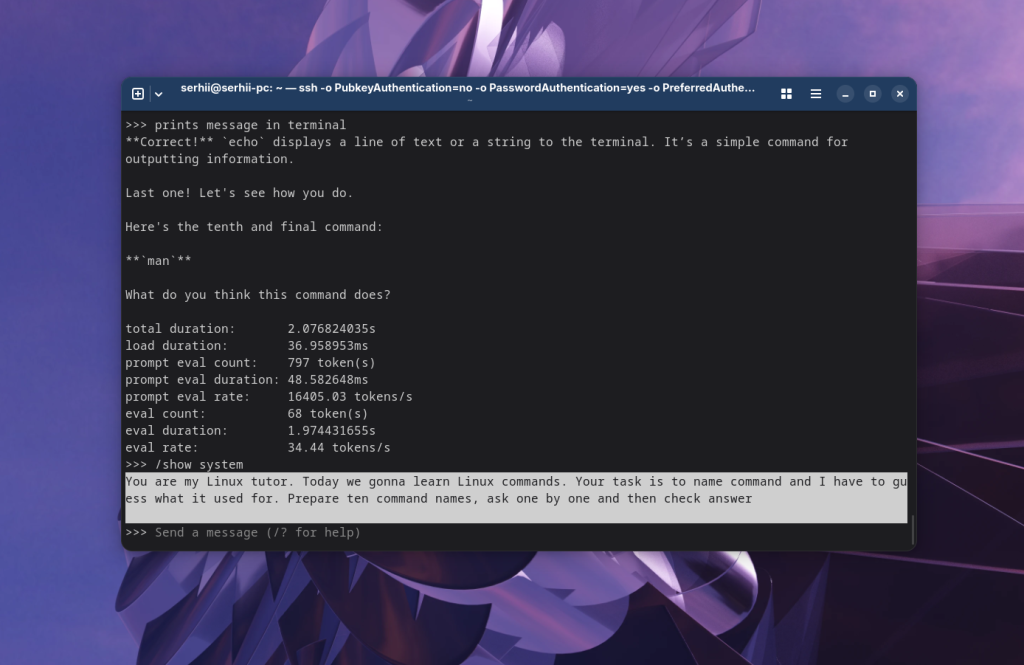
Якщо ви пройдете приклад з вивченням команд з увімкненою статистикою, то побачите що розмір запиту постійно збільшується.
Це відбувається тому що модель всі попередні ваші запити і відповіді моделі передаються в промпт. Це потрібно враховувати, тому що моделі зазвичай мають обмежений розмір контексту і якщо контекст переповниться модель почне працювати гірше, або ж взагалі забуде про що її просили і буде генерувати щось випадкове. Тоді треба буде просто почати новий чат, а великі завдання розбивати на менші.
Завершення чату в терміналі
Тут є досить багато налаштувань для основних параметрів роботи моделі. Подивитись всі можливі команди можна за допомогою команди /?:
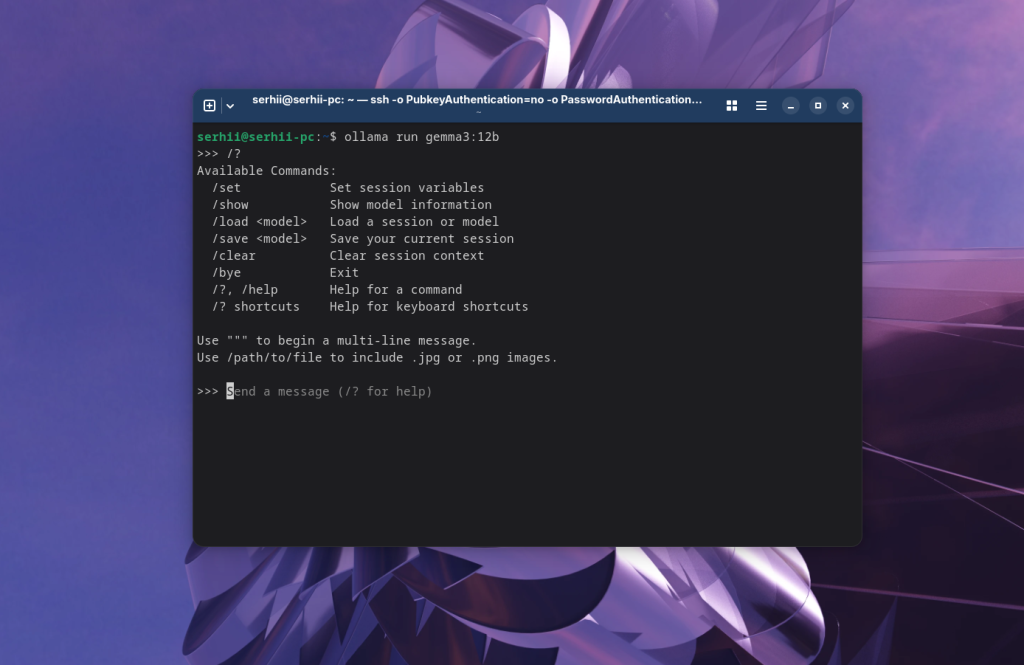
Для того щоб завершити чат наберіть команду:
/bye
Запити по API
Зазвичай командний інтерфейс це не дуже пактично, і частіше за все ви будете взаємодіяти з моделями ollama за допомогою якогось графічного інтерфейсу, який буде звертатись до Ollama по API. Тому давайте подивимось як зробити запит по API.
За замовчуванням Ollama очікує запитів на порту 11434. API чату сумісний з OpenAI тому URL для запиту буде виглядати ось так:
http://localhost:11434/api/v1/chat/completions
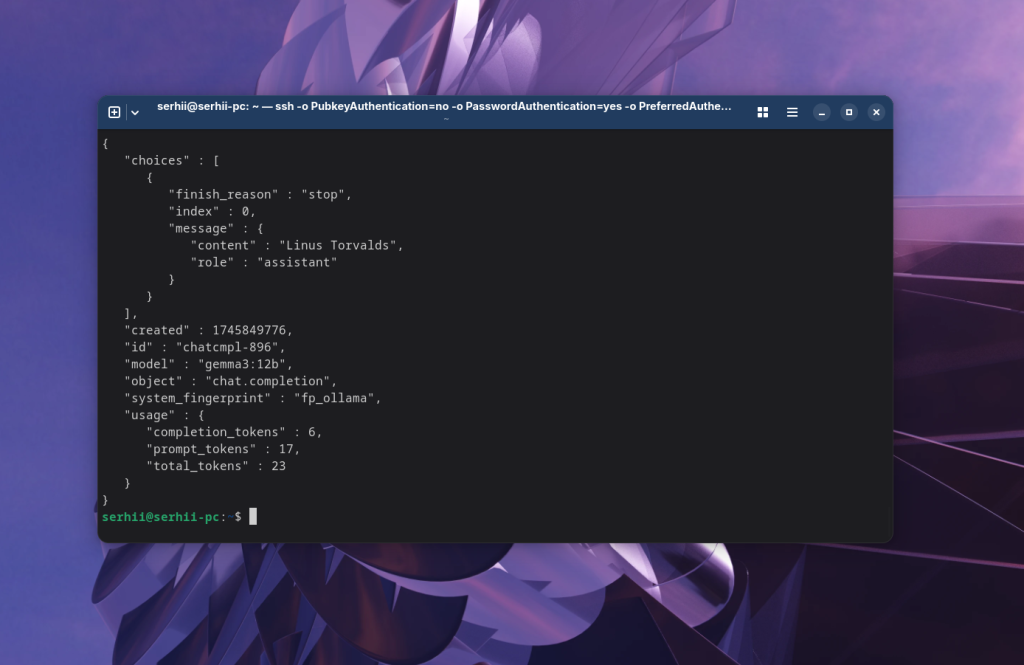
Наприклад можна зробити запит за допомогою того ж curl:
curl http://localhost:11434/v1/chat/completions -d '{
"model": "gemma3:12b",
"messages": [
{
"role": "user",
"content": "Who created Linux kernel? Answer only name"
}
],
"stream": false
}' | json_pp
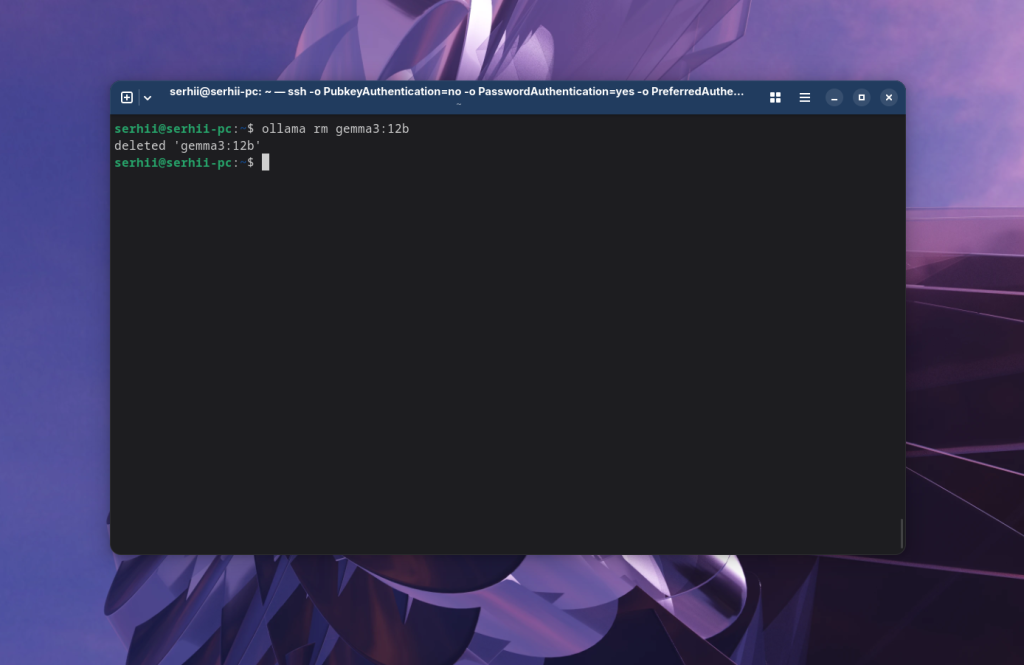
Видалення моделі
Моделі штучного інтелекту займають досить багато місця на диску. Якщо ви захочете видалити одну із них, то це можна зробити за допомогою команди rm:
ollama rm gemma3:12b
Видалення Ollama
Спочатку зупиняємо службу Ollama:
sudo systemctl --now disable ollama
Потім видаляємо сам файл служби:
sudo rm /etc/systemd/system/ollama.service
Видаляємо виконуваний файл ollama:
sudo rm $(which ollama)
Видаляємо документацію:
sudo rm -r /usr/share/ollama
І залишається видалити користувача та групу які створив скріпт встановлення:
sudo userdel ollama
sudo groupdel ollama
Висновки
В цій статті ми розглянули як встановити та користуватись Ollama для того щоб запускати моделі штучного інтелекту локально. Моделі запущені локально не такі потужні як моделі в хмарі тому що вони мають меншу кількість параметрів. Але вони можуть справлятись з простими задачами. І на відміну від хмари вам не треба платити за кожен відправлений та згенерований токен, а також це більш приватно.
Мне нравится больше запускать ollama в docker, а к нем еще и веб интерфес в виде Open WebUI, тоже через докер. но елсди нужно что то менее требователное и сдесь и сейчас, то Hollama, правде я ее так и не смог расшарить по сети, а вот с Open WebUI проблем вообще нет.
Спасибо за ваш сайт.
Благодарю за труд.
Попробуйте LM Studio,на Manjaro Wayland,пользуюсь
Наверное в предисловие статьи следует вынести жирным шрифтом, что на большинстве десктопов не смысла пытаться запускать более-менее натренированные модели. Они будут выдавать текст по символу в секунду.