Искусственный интеллект набирает довольно большую популярность в последнее время. Причем наряду с моделями, доступными в облаке, многие пользователи хотят иметь возможность использовать искусственный интеллект локально. Как бы там ни было, это значительно безопаснее, поскольку ваши данные никуда не передаются, а также надежнее, так как при использовании моделей локально вас не смогут заблокировать.
Но у такого подхода есть и проблемы. Аппаратные возможности персональных компьютеров довольно ограничены, поэтому возможности моделей, запущенных локально, будут значительно меньше, чем тех, которые доступны в облаке. В этой статье мы рассмотрим что это такое, как это работает, а также как использовать Ollama для запуска моделей искусственного интеллекта локально.
Содержание статьи
Необходимые основы
Ollama имеет достаточно простой интерфейс командной строки, а загрузить и запустить модель можно выполнив несколько команд. Поэтому начать работать с этим инструментом довольно просто. Реализовано это всё на основе llama.cpp, а модели AI сохранены в формате GGUF (GPT Generated Unified Format), но нам этим заниматься не нужно, так как загрузку моделей и конфигурирование llama.cpp берёт на себя Ollama.
Но для того чтобы понять какие модели можно запускать, а какие нет на вашем компьютере, вам нужно знать некоторые основы. Если очень упростить, модель искусственного интеллекта это огромный набор чисел, расположенных в виде определенной структуры и часто скомбинированных в большое количество слоев. Количество этих чисел и есть количество параметров модели.
Когда мы выполняем запрос к модели, наш запрос также конвертируется в числа, и эти числа умножаются на числа, которые были в модели. Конечно, это не простая операция, и всё это происходит с учётом структуры связей в модели и её слоёв, после чего мы получаем результат. Это очень упрощённо и, возможно, не совсем точно, но отражает в общих чертах происходящий процесс.
Поскольку необходимо выполнить очень большое количество математических операций за короткий промежуток времени, для запуска моделей искусственного интеллекта используются видеокарты. Видеокарты имеют множество процессорных ядер, которые выполняют такие задачи значительно быстрее процессора. Но для того чтобы это заработало, все числа модели и ваш запрос должны поместиться в видеопамять вашей видеокарты.
Размер модели
Для каждой модели на сайте ollama указывается количество параметров и её размер:
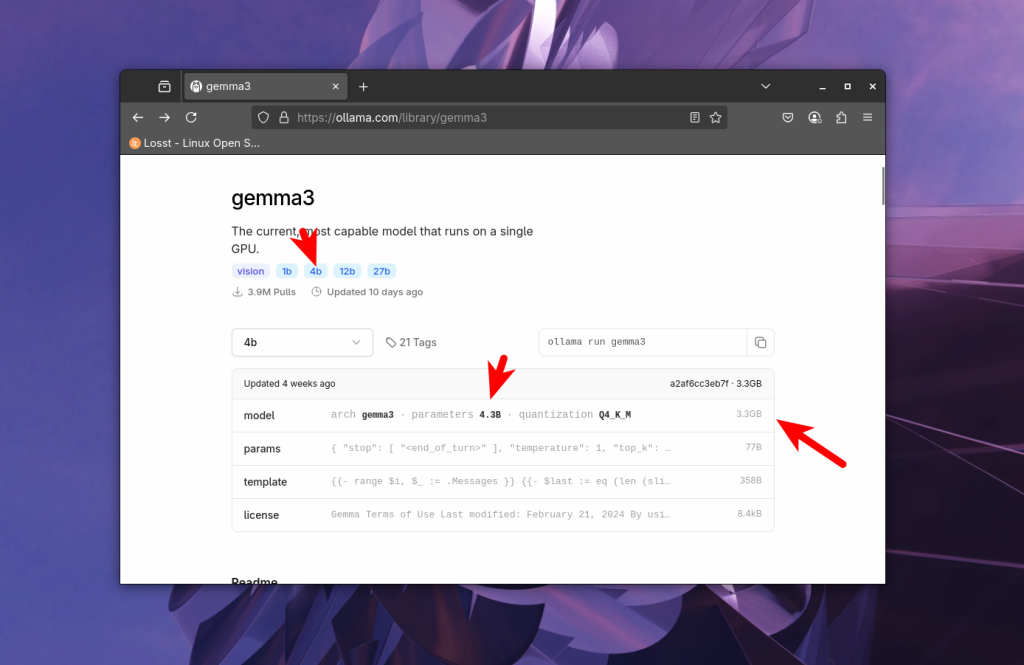
Конечно, можно загружать в память видеокарты только часть модели, если там не хватает видеопамяти, а все остальное хранить в оперативной памяти. Ollama поддерживает это по умолчанию. Но тогда скорость взаимодействия с моделью падает в десятки раз, так как компьютеру приходится часто обращаться к оперативной памяти и процессору, которые не такие быстрые как видеокарта.
Поэтому разработчики моделей стараются создавать модели различных размеров, например 1b, 4b, 12b, 27b. Здесь b означает миллиард. 12b означает - 12 миллиардов параметров. Если будем использовать для хранения числа с плавающей точкой Float16 (FP16), то в полном размере модель на 12 миллиардов параметров будет занимать 12 000 000 000 * 2 байта = 24 гигабайта. Это максимальная точность, с которой в ollama доступны модели. Учитывая, что нужно еще где-то разместить данные запроса (контекст), то для запуска такой модели нам понадобилась бы видеокарта более чем на 24 гигабайта видеопамяти.
Квантование
Видеокарты с большим объемом памяти стоят довольно дорого, поэтому была придумана квантизация. Точность чисел, из которых состоит модель, уменьшается. Так сказать, обрезается хвост, и число, которое занимало 2 байта, начинает занимать байт или даже половину. Это, конечно, влияет на качество работы модели, и чем более квантизована модель - тем хуже она будет работать, но тем меньше памяти будет требовать. Вот кванты, которые поддерживаются ollama:
- fp16 - максимум, 16 бит, 2 байта
- q8 - 8 бит - половина байта
- q4 - 4 бита - 0,25 байта
Конечно, существуют различные модификации методов квантизации, которые позволяют улучшить качество работы моделей при той же экономии памяти, но я не буду здесь о них писать. При выборе модели на сайте Ollama можно выбрать квант в выпадающем списке:
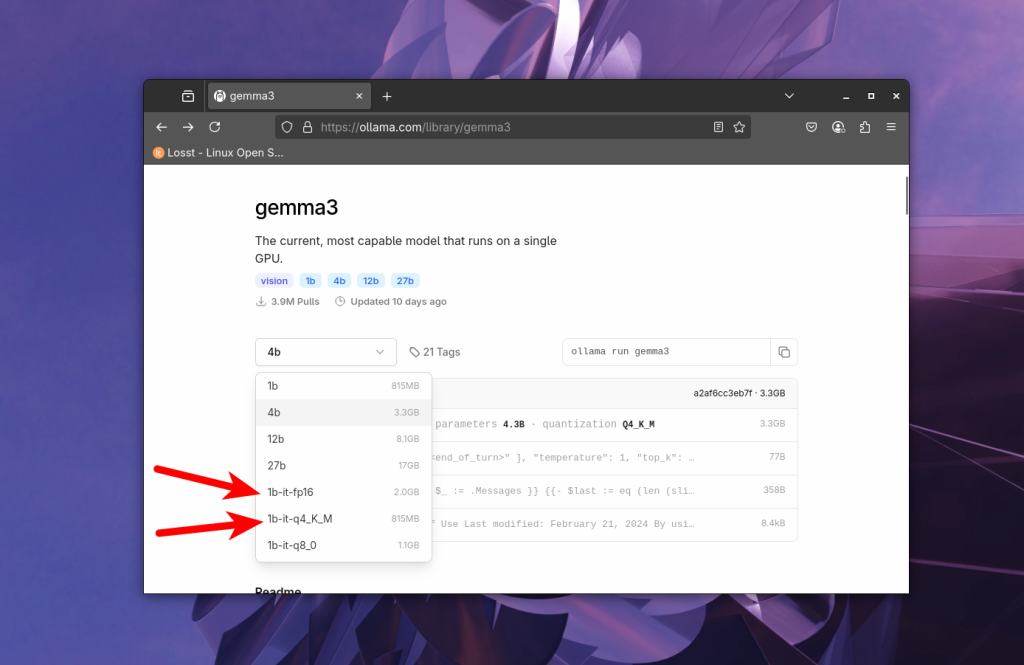
Оптимально использовать fp16 для production, а для тестов и всего остального можно пользоваться q4. Например, модель gemma3 на 12 миллиардов параметров занимает 24 Гб, а в Q4 уже 8.8 Гб, что означает возможность её запуска на RTX 3060, имеющей 12 Гб видеопамяти.
Этого будет достаточно для того чтобы понять какую модель можно загружать, а теперь давайте перейдем непосредственно к установке Ollama.
Установка Ollama
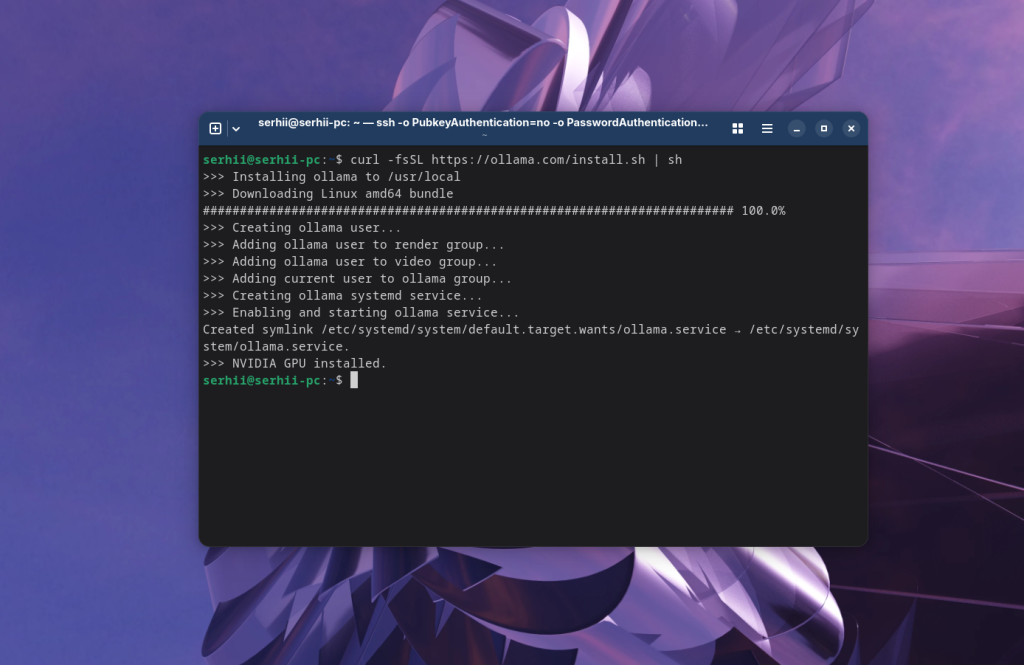
Для установки Ollama достаточно открыть сайт https://ollama.com/ и нажать кнопку Download. Откроется страница, на которой будет команда установки для любого дистрибутива Linux. Фактически это curl команда, которая загрузит и запустит скрипт установки ollama в вашей системе. На момент написания статьи команда выглядит так:
curl -fsSL https://ollama.com/install.sh | sh
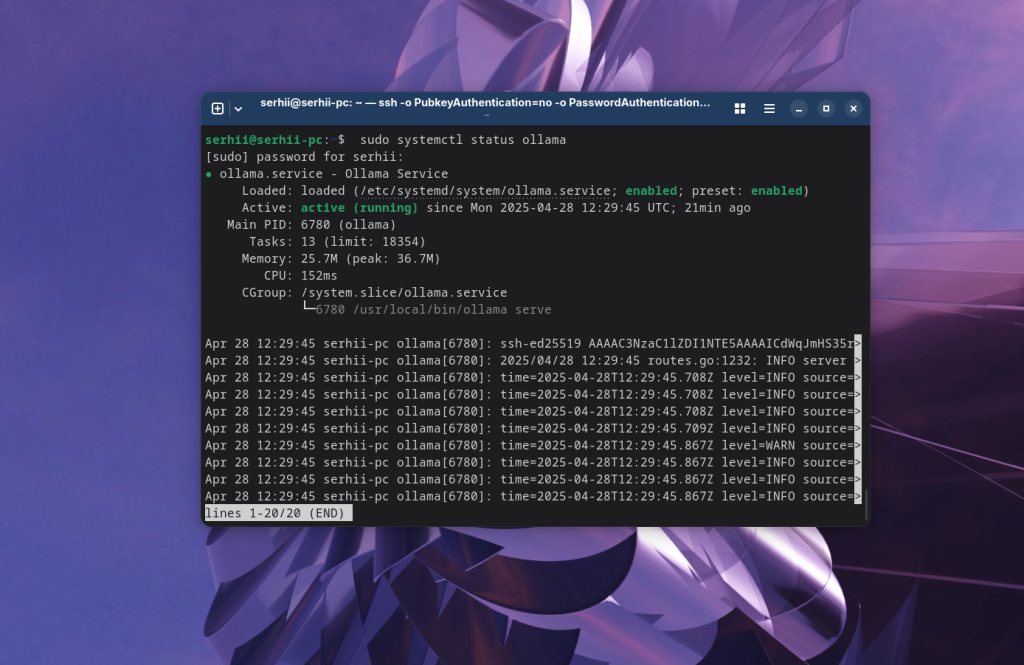
После завершения выполнения сценария установки можно проверить что служба ollama запущена:
sudo systemctl status ollama
Как использовать ollama
После этого можно переходить к использованию. Прежде всего давайте рассмотрим как загрузить модель.
Загрузка модели
Модель нужно выбрать на сайте Ollama с помощью поиска. Например gemma3:
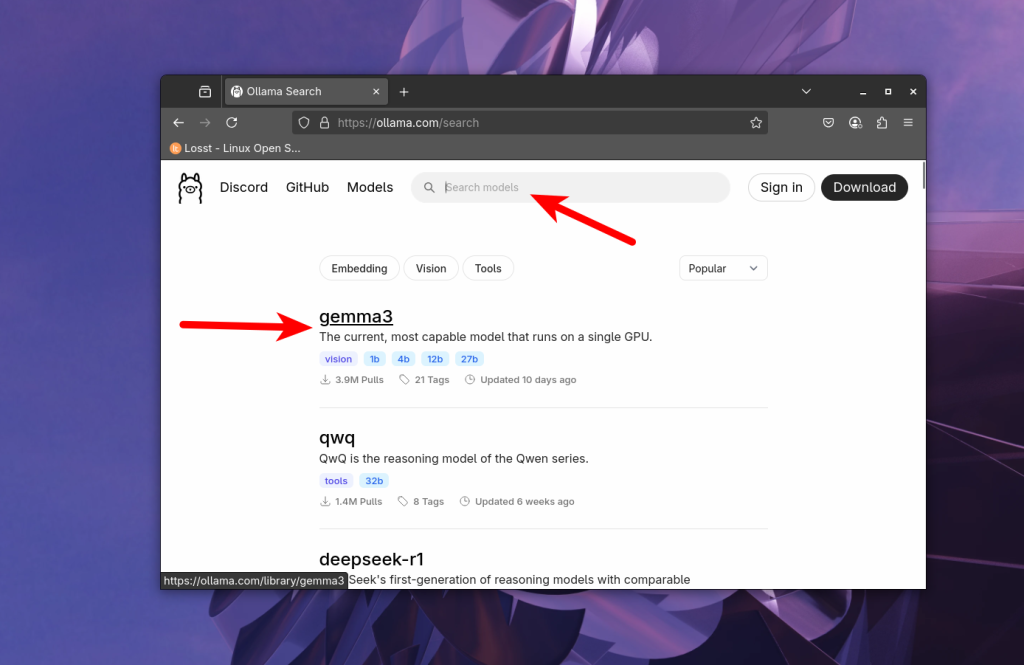
Далее в выпадающем списке выбираем количество параметров и квантизацию модели, например 12b, по умолчанию обычно используется квантизация Q4_K_M:
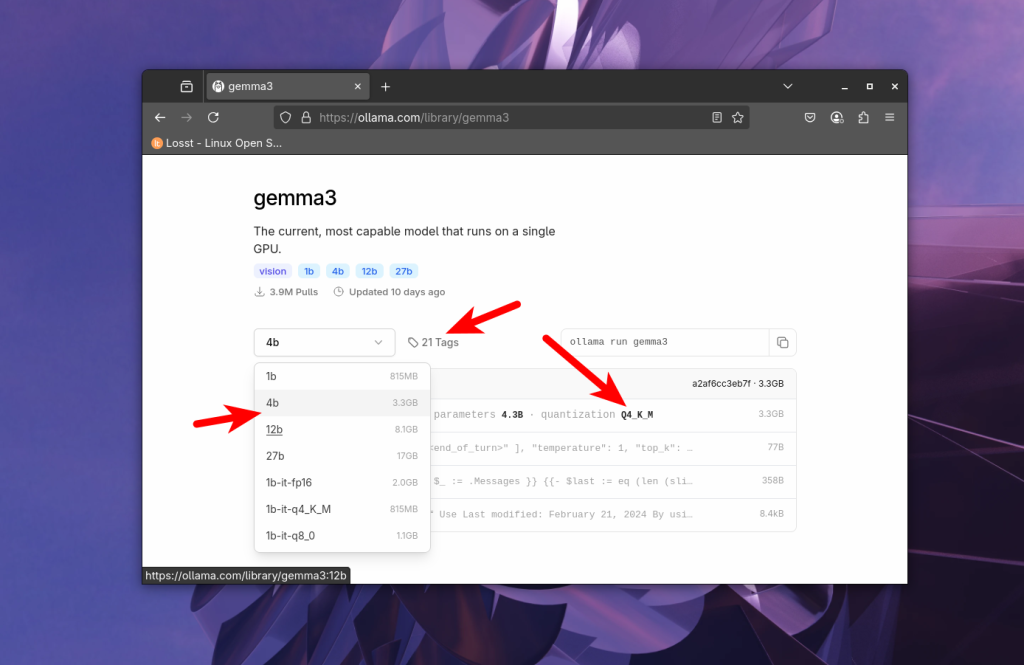
Чтобы посмотреть все доступные варианты нужно перейти на вкладку tags:
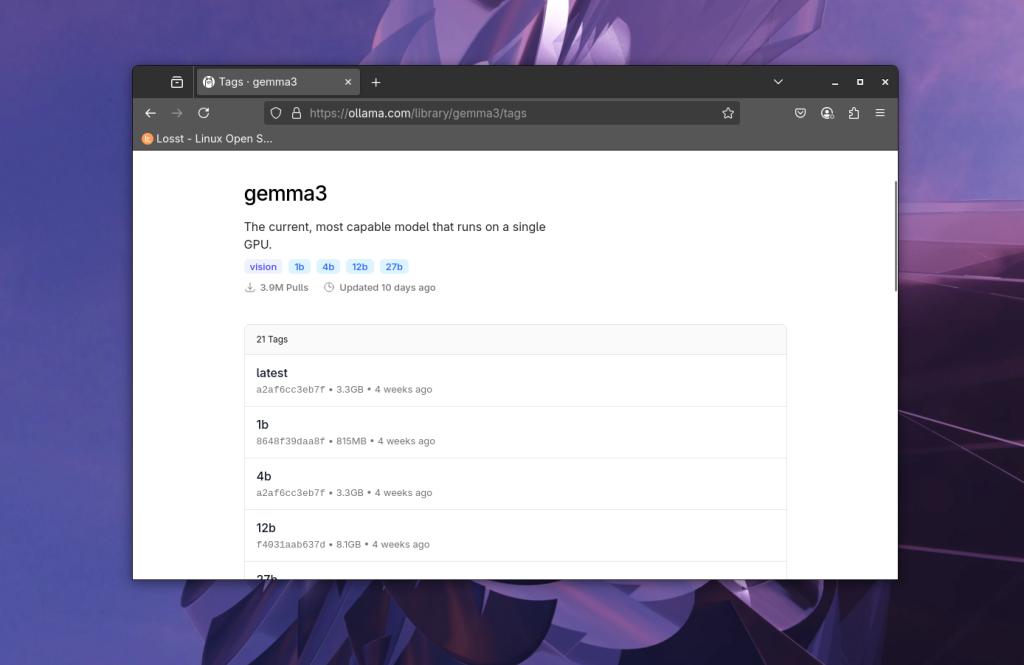
После выбора модели можно увидеть информацию о ней, количество параметров, квант, размер и т.д.:
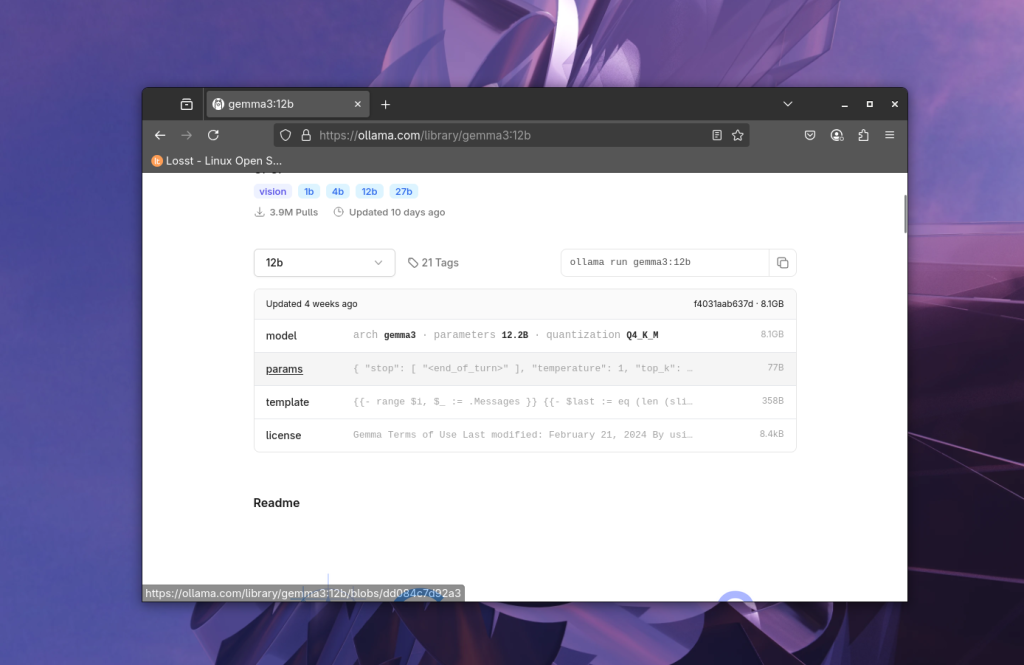
И справа напротив выпадающего списка видим команду для запуска модели, в которой указано её название:
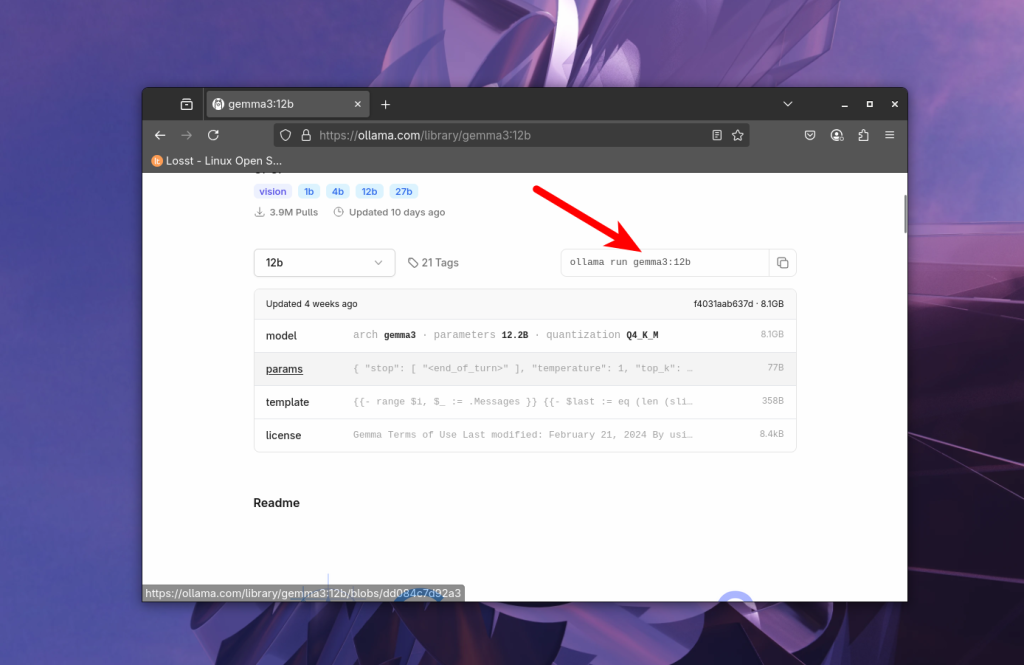
Можно сразу же выполнить предложенную команду, и она не только загрузит её, но и запустит чат с ней в терминале. Или же можно просто загрузить модель с помощью команды pull:
ollama pull gemma3:12b
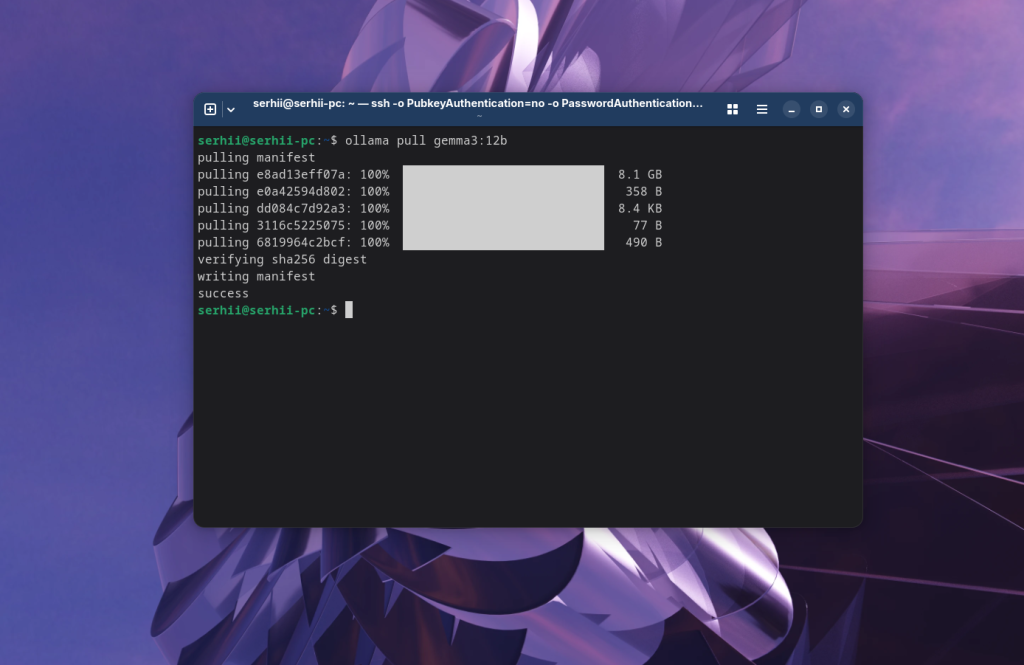
Также можно полностью указать квант, который берем из названия тега:
ollama pull gemma3:12b-it-q4_K_M
Запуск модели в терминале
После того как модель загружена можно посмотреть список моделей доступных локально с помощью команды list:
ollama list
Чат с нужной моделью можно запустить в терминале с помощью той же команды run:
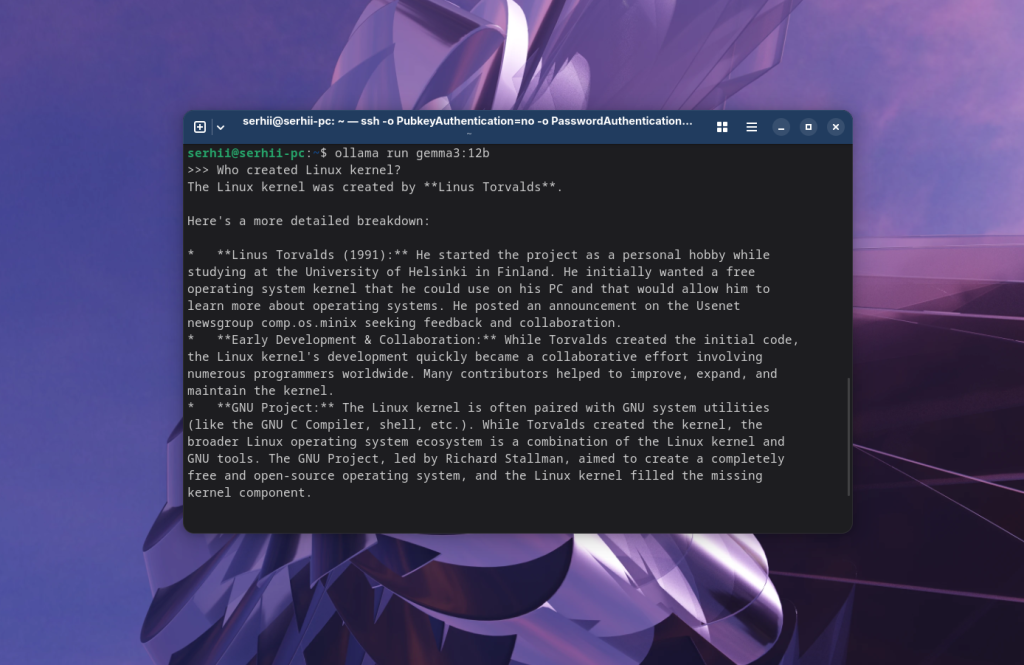
ollama run gemma3:12b
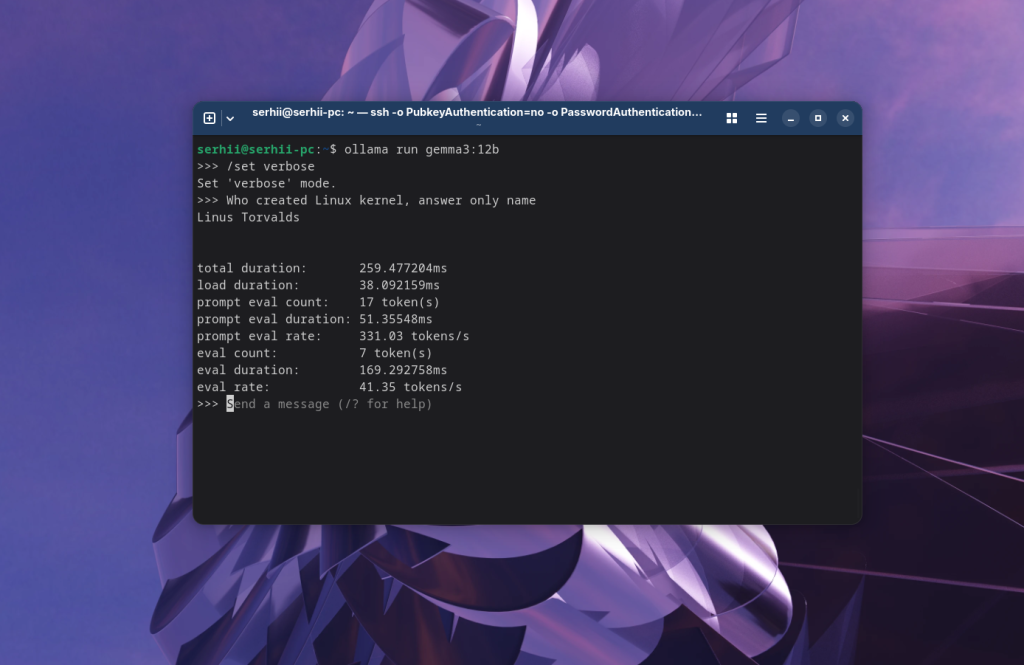
Здесь можно задавать вопросы для общения с моделью. Например: Кто создал ядро Linux:
Ollama может загружать модели как в видеопамять, так и выгружать часть слоев в оперативную память, если видеопамяти не хватает. Это всё происходит без вашего участия. Если вы используете видеокарту Nvidia, то для проверки использования видеопамяти можно воспользоваться утилитой nvidia_smi:
nvidia_smi
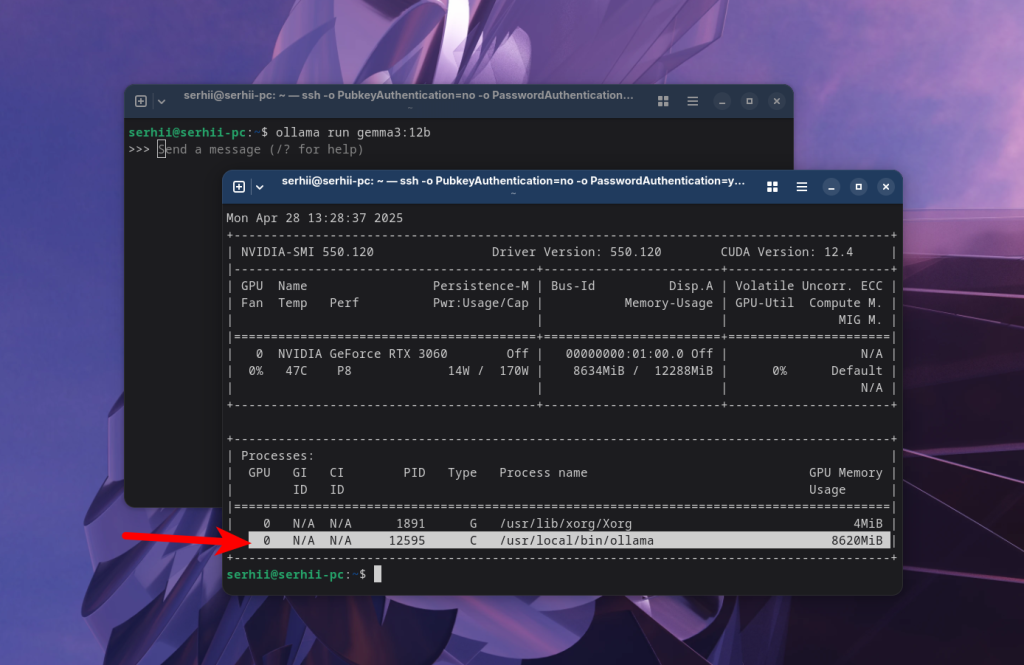
Здесь можно видеть, что чуть больше 8 Гб видеопамяти использует Ollama, а значит модель загружена в видеопамять.
Статистика использования
При использовании искусственного интеллекта размер запросов (промптов), которые вы передаете в модель, а также ответов, которые получаете, измеряется не в количестве символов, а в количестве токенов. Обычно на слово приходится около полутора-двух токенов. Вы можете включить вывод статистики в чате с помощью команды:
/set verbose
В статистике можно увидеть не только количество полученных и сгенерированных токенов, но также скорость генерации, количество токенов в секунду в поле eval rate:
Системный запрос модели
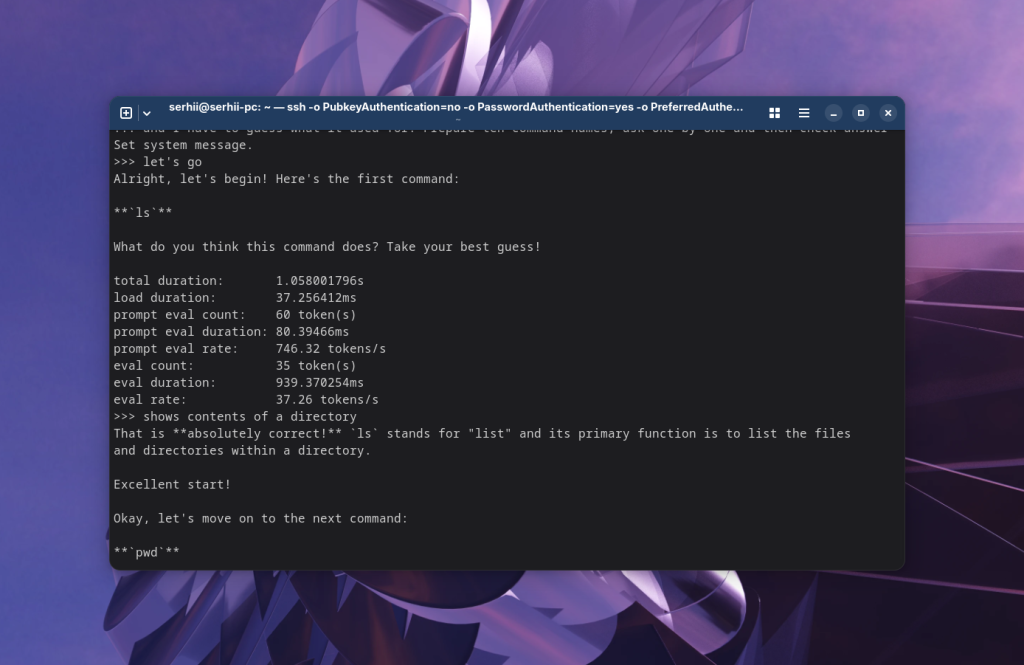
При взаимодействии с моделью искусственного интеллекта указывается не только текущий запрос, но и системный. По умолчанию в системном запросе обычно находится что-то вроде "you are helpful assistant" или пусто. Если вам нужно, чтобы модель выполняла какую-то специфическую задачу, вы можете прописать её в системном запросе с помощью команды /set system. Например:
You are my Linux tutor. Today we gonna learn Linux commands. Your task is to name command and I have to guess what it used for. Prepare ten command names, ask one by one and then check answer.
После этого достаточно написать модели что-нибудь, чтобы она начала работать. Например, let's go:
Посмотреть текущий системный запрос можно с помощью команды:
/show system
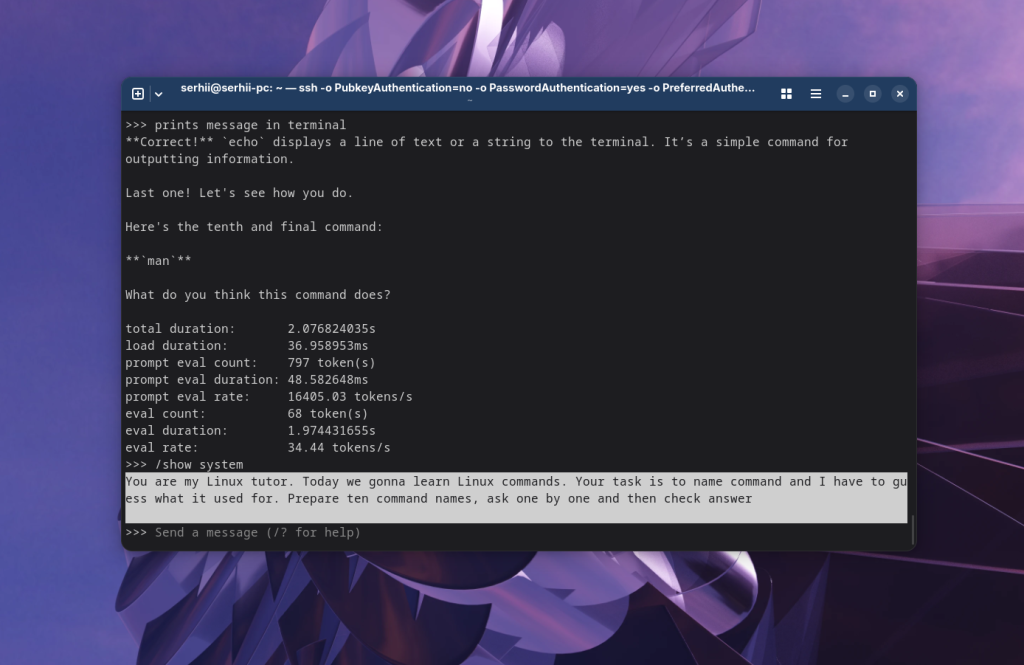
Если вы пройдете пример с изучением команд с включенной статистикой, то увидите, что размер запроса постоянно увеличивается.
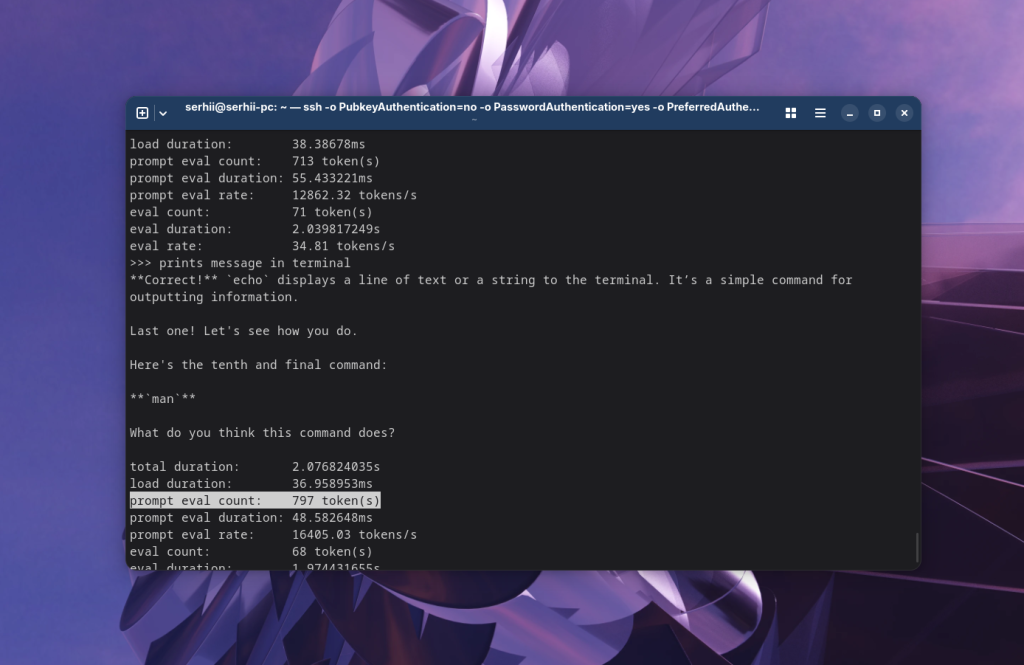
Это происходит потому что модели передаются в промпт все предыдущие ваши запросы и ответы модели. Это нужно учитывать, так как модели обычно имеют ограниченный размер контекста, и если контекст переполнится, модель начнет работать хуже или вовсе забудет о чем её просили и будет генерировать что-то случайное. Тогда придется просто начать новый чат, а большие задачи разбивать на меньшие.
Завершение чата в терминале
Здесь есть довольно много настроек для основных параметров работы модели. Посмотреть все возможные команды можно с помощью команды /?:
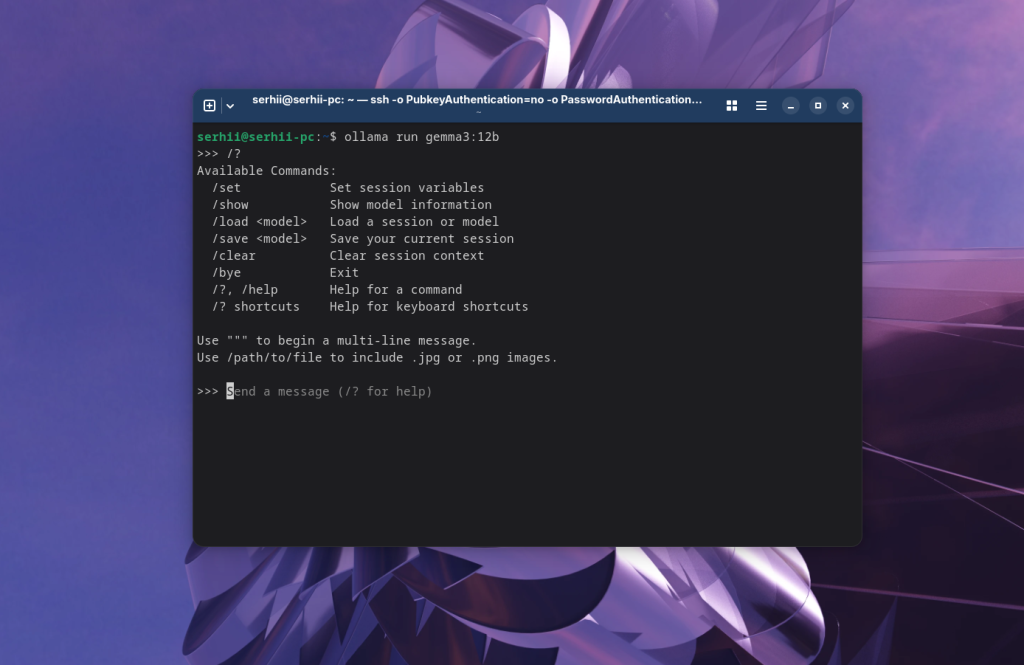
Для того чтобы завершить чат наберите команду:
/bye
Запросы по API
Обычно командный интерфейс не очень практичен, и чаще всего вы будете взаимодействовать с моделями ollama с помощью какого-либо графического интерфейса, который будет обращаться к Ollama по API. Поэтому давайте посмотрим, как сделать запрос по API.
По умолчанию Ollama ожидает запросов на порту 11434. API чата совместим с OpenAI, поэтому URL для запроса будет выглядеть так:
http://localhost:11434/api/v1/chat/completions
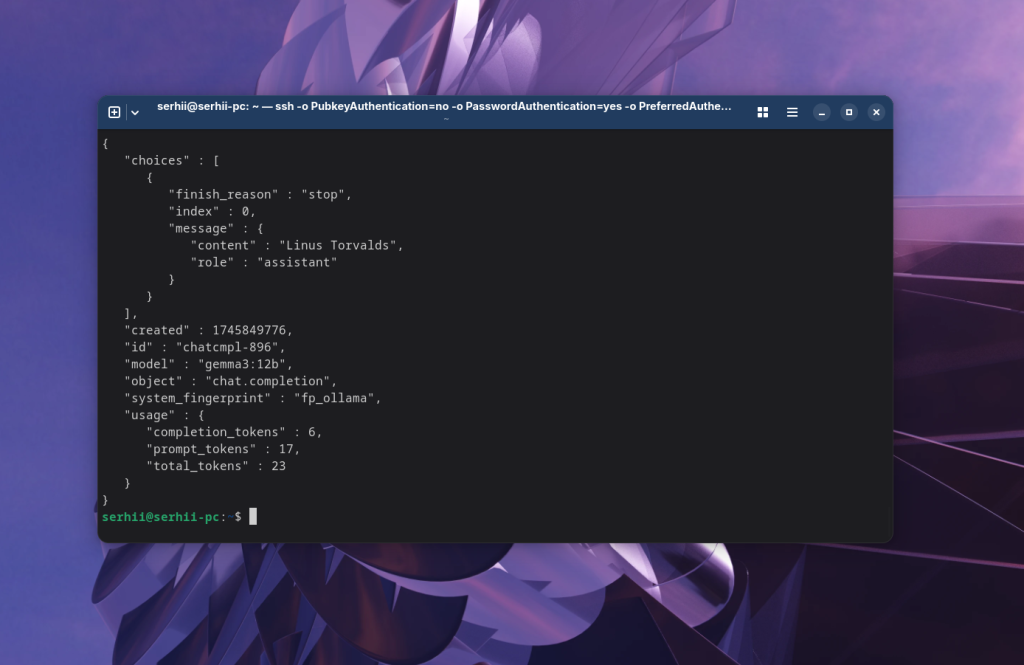
Например, можно сделать запрос с помощью того же curl:
curl http://localhost:11434/v1/chat/completions -d '{
"model": "gemma3:12b",
"messages": [
{
"role": "user",
"content": "Who created Linux kernel? Answer only name"
}
],
"stream": false
}' | json_pp
Удаление модели
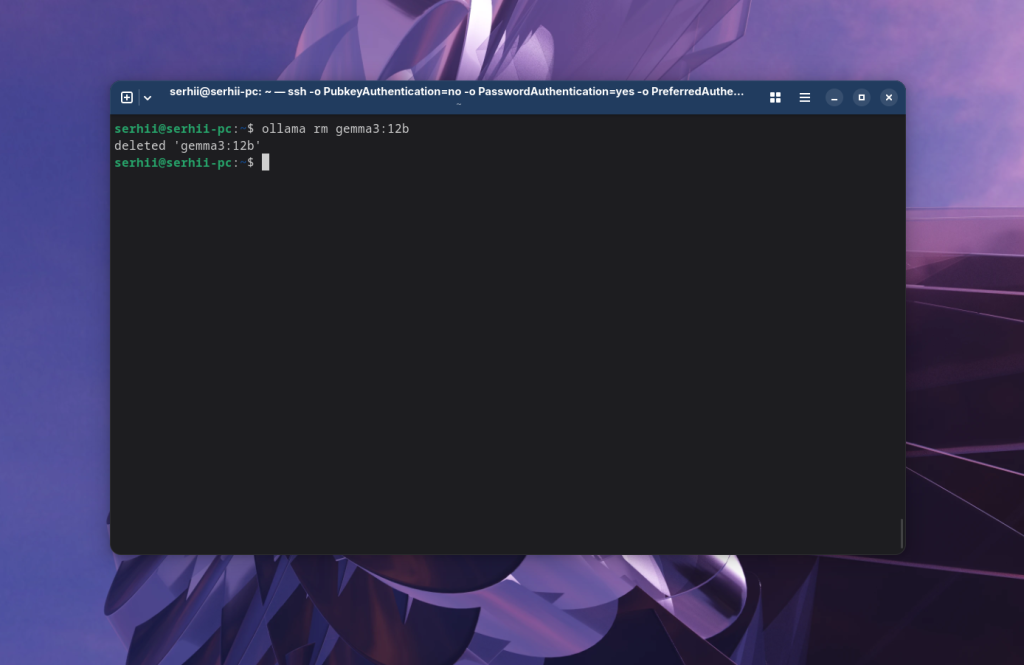
Модели искусственного интеллекта занимают довольно много места на диске. Если вы захотите удалить одну из них, это можно сделать с помощью команды rm:
ollama rm gemma3:12b
Удаление Ollama
Сначала останавливаем службу Ollama:
sudo systemctl --now disable ollama
Затем удаляем сам файл службы:
sudo rm /etc/systemd/system/ollama.service
Удаляем исполняемый файл ollama:
sudo rm $(which ollama)
Удаляем документацию:
sudo rm -r /usr/share/ollama
И остается удалить пользователя и группу, которые создал скрипт установки:
sudo userdel ollama
sudo groupdel ollama
Выводы
В этой статье мы рассмотрели как установить и использовать Ollama для запуска моделей искусственного интеллекта локально. Модели, запущенные локально, не такие мощные как модели в облаке, поскольку они имеют меньшее количество параметров. Однако они могут справляться с простыми задачами. И в отличие от облака, вам не нужно платить за каждый отправленный и сгенерированный токен, к тому же это более приватно.
Мне нравится больше запускать ollama в docker, а к нем еще и веб интерфес в виде Open WebUI, тоже через докер. но елсди нужно что то менее требователное и сдесь и сейчас, то Hollama, правде я ее так и не смог расшарить по сети, а вот с Open WebUI проблем вообще нет.
Спасибо за ваш сайт.
Благодарю за труд.
Попробуйте LM Studio,на Manjaro Wayland,пользуюсь
Наверное в предисловие статьи следует вынести жирным шрифтом, что на большинстве десктопов не смысла пытаться запускать более-менее натренированные модели. Они будут выдавать текст по символу в секунду.