Elasticsearch - это одна из самых популярных систем для организации поиска, основанная на библиотеке Lucene. Раньше на этом сайте публиковалась статья в которой было рассказано как установить и настроить Elasticsearch, а также как использовать основные типы запросов, фильтры и группировку данных.
В этой статье я хочу сосредоточится только на поиске. Мы рассмотрим как работают анализаторы, токенизаторы, а также разберемся как всё это эффективно использовать для организации поиска.
Содержание статьи
Как работает поиск в Elasticsearch
Для того чтобы поиск работал эффективно и был достаточно релевантным недостаточно просто сохранить заголовок текста или сам текст в поисковый индекс. Этот текст должен быть разбит на токены. Это части текста по которым будет выполнятся поиск. По умолчанию Elasticsearch использует анализатор standard для всех полей с типом text. Этот анализатор разбивает текст на слова согласно алгоритму сегментации Unicode и работает с большинством языков.
Это можно проверить на примере. У Elasticsearch есть API, которое позволяет посмотреть на какие токены будет разбит текст при использовании определённого анализатора. Давайте рассмотрим пример. В этой статье я предлагаю использовать Kibana для запросов к Elasticsearch, потому что запросы будут сложные и выполнять их в curl не удобно. Синтаксис API анализа выглядит следующим образом:
_analyze
{
"analyzer": "название_анализатора",
"text": "текст для анализа"
}
Для примера давайте посмотрим каким образом будет разбито предложение "В чащах юга жил был цитрус, да но фальшивый экземпляр":
POST _analyze
{
"analyzer" : "standard",
"text" : "В чащах юга жил был цитрус, да но фальшивый экземпляр"
}
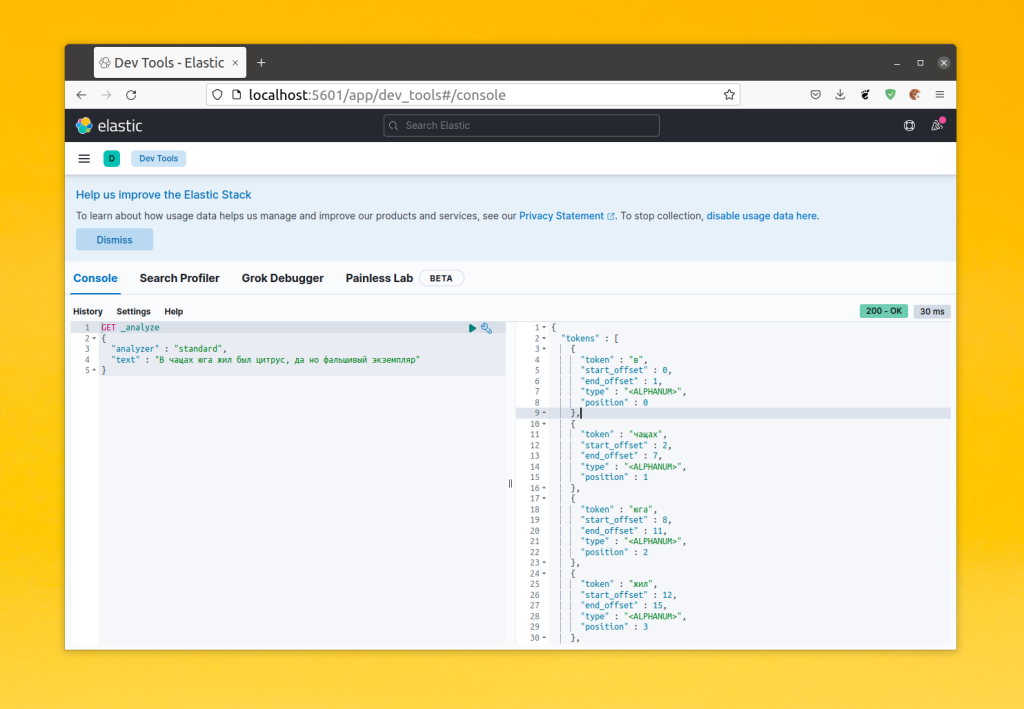
Как видите, текст разбивается на слова и если пользователь будет искать слово "чащах", то сможет найти этот документ. Такой алгоритм разбиения используется как на этапе индексирования, так и на этапе поиска. Поэтому поисковый запрос тоже будет разбит на токены и если будут совпадения то документ будет найден. Обратите внимание, что ElasticSearch использует анализатор как при индексации, так и при поисковом запросе. Конечно, на то как будут сопоставляться сами токены влияет какой тип запроса будет использован. Например: match, match_phrase, multi_match, query_string, а также будет ли включён нечёткий поиск Elasticsearch (fuzzines). Но в целом, это работает именно так. Меняя анализаторы и тип поискового запроса можно делать поиск более релевантным для вашего проекта.
Настройка поиска в ElasticSearch
Для следующих примеров давайте создадим индекс под названием test_index в котором будет два поля: title и content. Оба они будут иметь тип text и пока что будут использовать анализатор standard:
PUT test_index
{
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Затем добавьте в получившийся индекс одну запись:
POST test_index/_doc
{
"title": "В чащах юга",
"content": "жил был цитрус, да но фальшивый экземпляр"
}
Теперь можно переходить к рассмотрению возможностей поиска ElasticSearch.
1. Поисковый запрос match
Запрос match ищет только по одному полю. Синтаксис этого поискового запроса выглядит вот так:
{
"match": {
"имя_поля":"запрос"
}
}
Например, вы можете попробовать найти ранее созданный документ:
GET _search?index=test_index
{
"query": {
"match": {
"title": "Чащах"
}
}
}
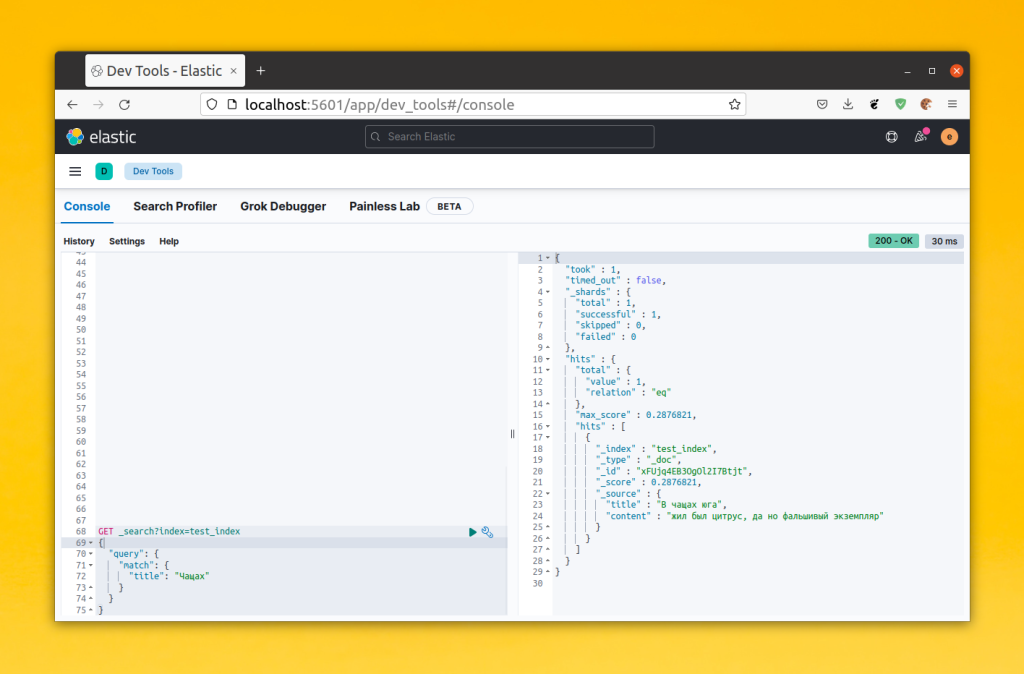
Обратите внимание, что match ищет полное соответствие по токену между токенами, на которые был разбит запрос. Если вы напишите чащ или ч, то ничего не будет найдено. Если вы хотите чтобы в результирующем документе были найдены все токены из запроса добавьте в него параметр operator со значением and:
GET _search?index=test_index
{
"query": {
"match": {
"query": "Чащах юга",
"operator": "and"
}
}
}
В таком виде документ будет найден, однако если вы добавите слово, которого нет в поле title, то ничего не будет найдено. Есть также поисковые запросы multi_match, match_phrase и т д. Например, если вы хотите поиск по нескольким полям Elasticsearch, используйте запрос multi_match, а если вам нужно вхождение полной фразы - используйте match_phrase.
2. Поисковый запрос query_string
Этот запрос работает похожим образом на match. Только по умолчанию он выполняет поиск по всем полям и поддерживает простые операторы в поисковом запросе, такие как AND и OR. Синтаксис query_string такой:
{
"query_string": {
"query": "запрос"
}
Например, вы можете запрос на поиск ранее созданного документа будет выглядеть вот так:
GET _search?index=test_index
{
"query": {
"query_string": {
"query": "Чащах OR юга"
}
}
}
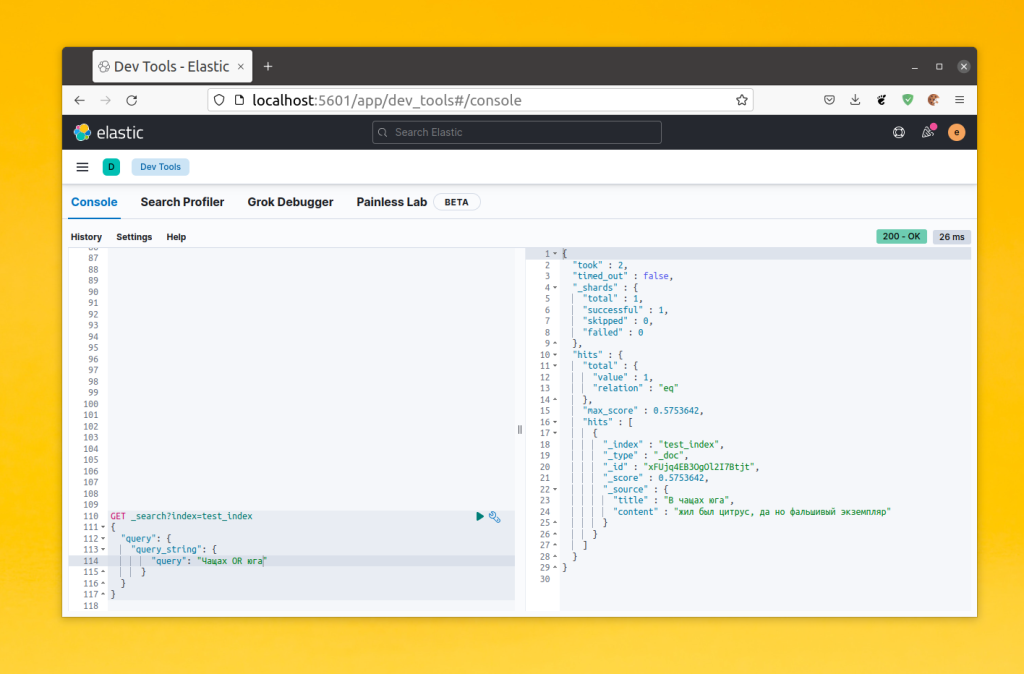
Также можно задать поле для поиска с помощью параметра default_field:
GET _search?index=test_index
{
"query": {
"query_string": {
"query": "Чащах OR юга",
"default_field": "title"
}
}
}
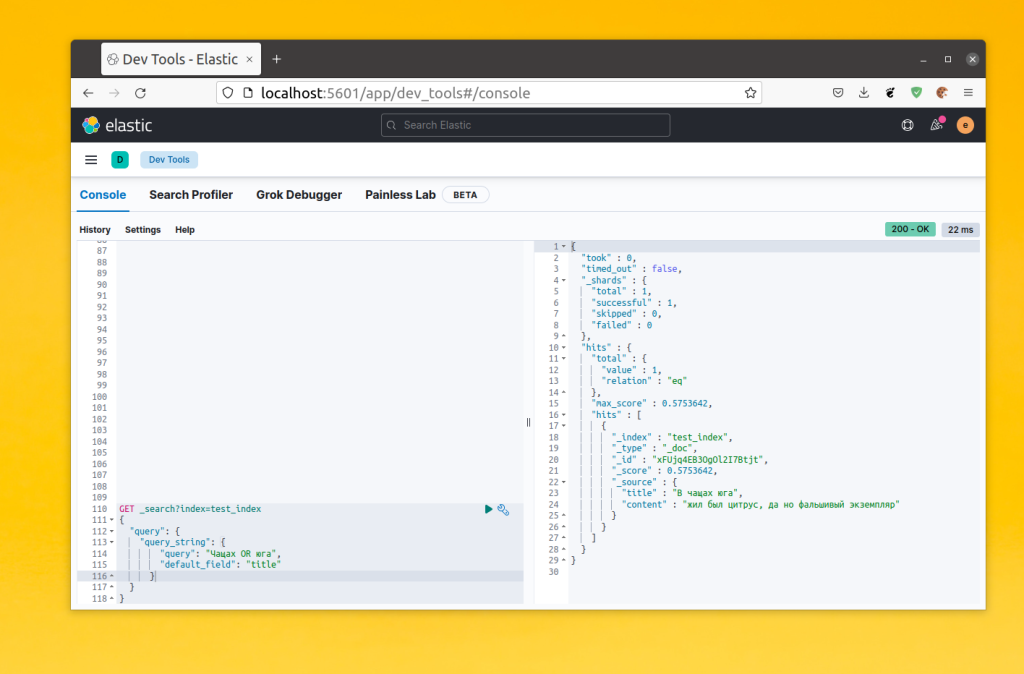
Тут можно делать довольно сложные запросы и указывать поле для поиска прямо в запросе. Однако если вы попытаетесь найти часть слова, то снова увидите что ничего не будет найдено. Такой поиск уже неплохо работает, но обычно пользователи хотят чтобы даже не полностью набранные слова дополнялись.
2. Нечеткий поиск
Кроме точного поиска, который мы рассмотрели выше, Elasticsearch поддерживает поиск неточных соответствий. Существует запрос fuzzy, а также в запрос match или query_string можно передать параметр fuzziness, который принимает максимальное расстояние между словами и включит нечеткий поиск Elasticsearch. Это всё работает на основе алгоритма расчёта расстояния Левенштейна. В этом алгоритме слова сравниваются посимвольно и если символ отличается, то расстояние увеличивается на единицу. Например, между словами чащах и кущах будет расстояние 2 потому что отличаются два символа. Таким образом, следующий запрос найдёт документ из примера:
GET _search?index=test_index
{
"query": {
"match": {
"title": {
"query": "кущах",
"operator": "and",
"fuzziness": 2
}
}
}
}
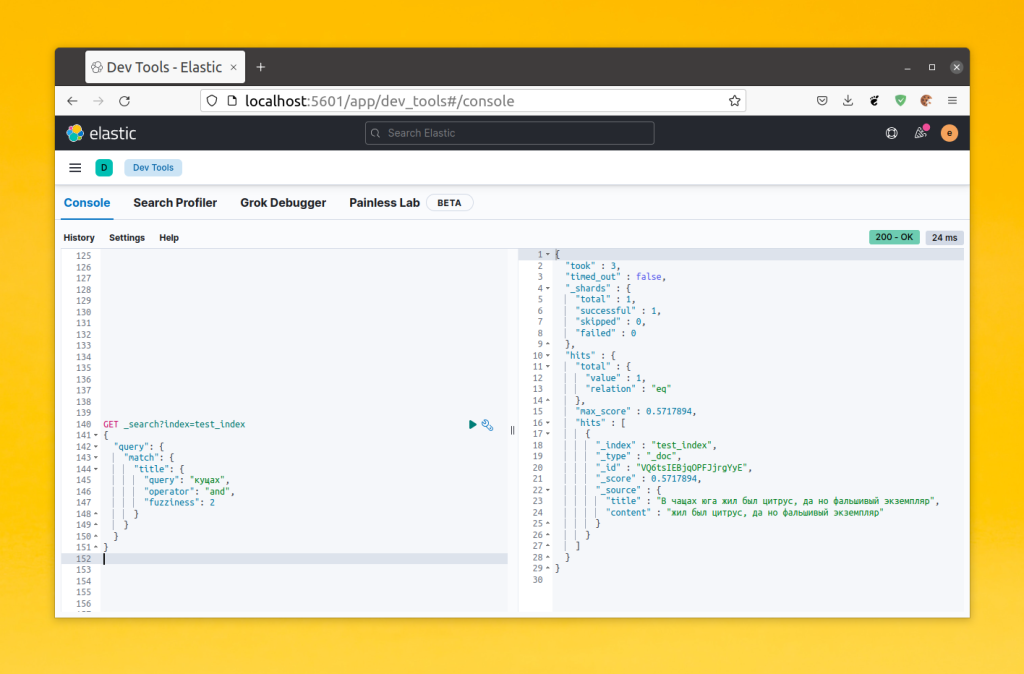
Однако, с fuzziness надо быть очень аккуратным. Она хороша для автодополнения и коррекции опечаток, но в реальном поиске она может добавить очень много не релевантных результатов в выдачу. Поэтому для улучшения поиска следует поискать другие способы. Например, менять настройки анализатора.
2. Анализатор языка
Вы можете улучшить поиск применив вместо стандартного анализатора анализатор языка, на котором выполняется поиск. У ElasticSearch есть анализаторы для множества языков, в том числе и для русского. Анализатор для русского языка разбивает предложение на токены и вместо слов старается сохранить их корневую форму:
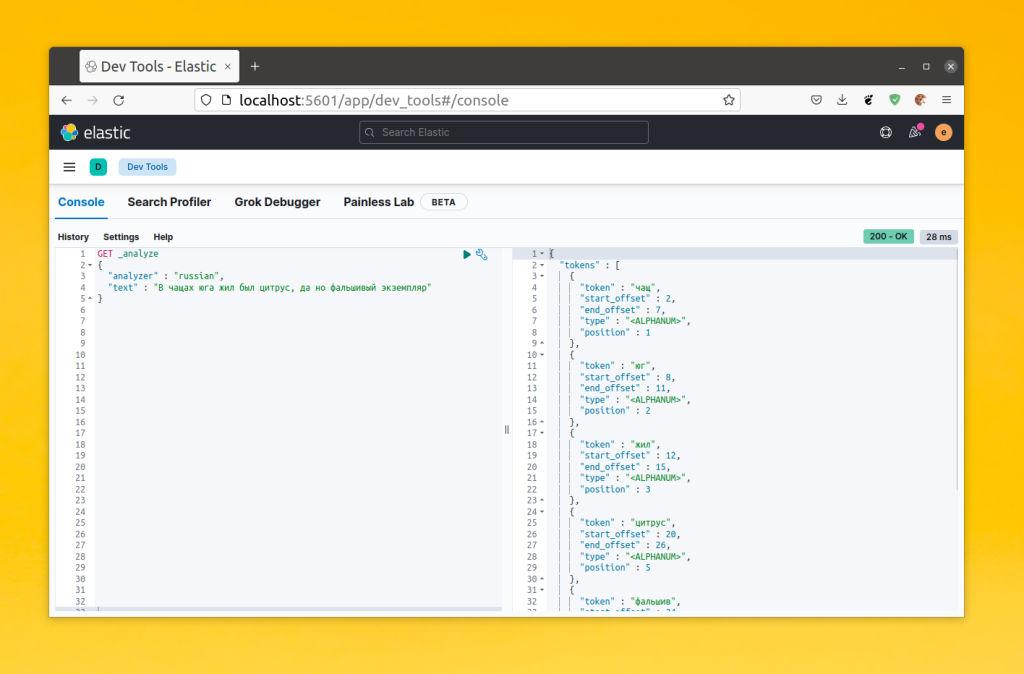
Для того чтобы изменить анализатор для поля надо пересоздать индекс. Сначала удалите старый индекс:
DELETE test_index
Рядом с типом поля достаточно указать анализатор с помощью параметра analyzer. Этот параметр задает анализатор для индексации. Желательно также задать анализатор для поискового запроса с помощью параметра search_analyzer, который бы работал подобным образом. Например:
PUT test_index
{
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "russian",
"search_analyzer": "russian",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "russian",
"search_analyzer": "russian",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Снова добавьте в индекс ту же запись и попробуйте искать её:
GET _search?index=test_index {
"query": {
"match": {
"title": "Чащ"
}
}
}
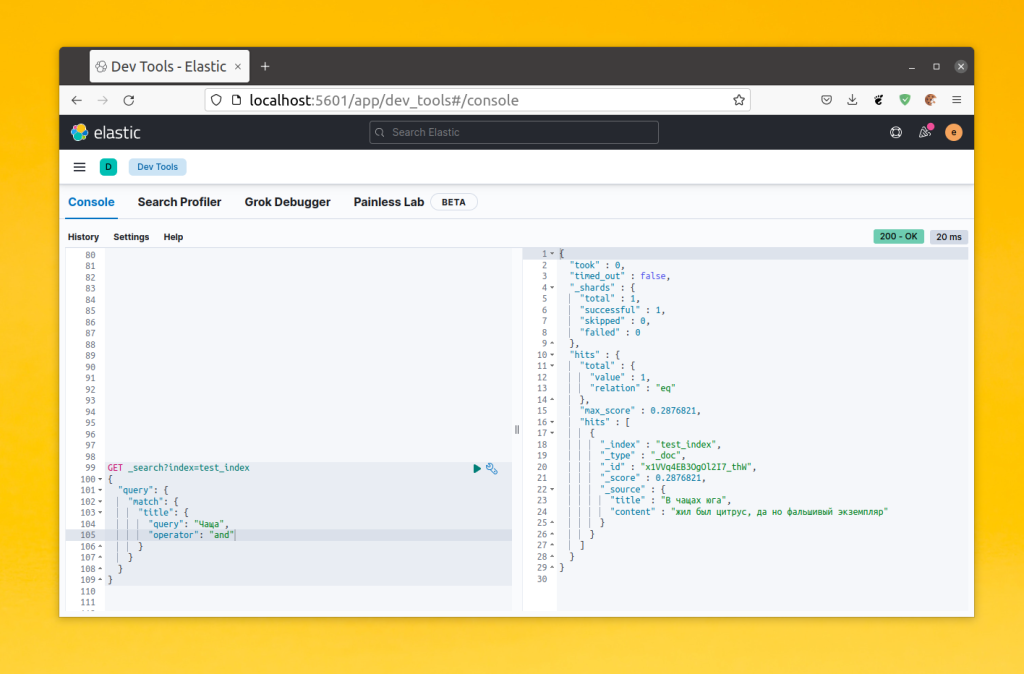
Как видите, теперь это работает лучше. Вы можете написать часть слова, слово в других формах и документ будет найден. Однако это подходит не для всех случаев. Если у вам нужно искать по сложным названиям, которых нет в словаре и которые состоят из букв, цифр и других символов, то это не будет работать так хорошо. Вы можете создать свой анализатор, который будет разбивать текст на нужные токены и применять к ним нужные изменения.
3. Создание своего анализатора
Для создания своего анализатора надо добавить раздел settings при создании индекса, а в него добавить раздел analysis. Сам анализатор составляется из настроек действий, которые будут применены к анализируемому тексту. Вот они:
- type - можно унаследовать свой анализатор от других, уже существующих анализаторов или же использовать тип custom для создания пустого анализатора.
- tokenizer - свой или стандартный токенизатор, который будет разбивать текст на токены.
- filter - список фильтров, которые будут применены к токенам.
Давайте для примера создадим простой анализатор. В качестве токенизатора будет использоваться whitespace, который разбивает текст на слова по пробелам, а в качестве фильтра будет применяться lovercase, который приводит запрос к нижнему регистру. Анализатор standard делает это автоматически, но в своём анализаторе надо это делать с помощью фильтра:
PUT test_index
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
]
}
}
}
},
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Вы можете снова добавить запись в индекс и проверить как это работает. Дальше давайте рассмотрим как добавить свой токенизатор для анализатора.
4. Выбор токенизатора
Большинство токенизаторов просто делят текст на слова, подобно тому как это делается в анализаторе standard, но учитывая разные условия. Вот основные из них:
- starnard - разбивает текст на слова;
- letter - разбивает текст на буквы;
- whitespace - разбивает текст на токены по пробелам;
- ngram - разбивает текст на n-грамы;
- edge_ngram - разбивает текст сначала на слова, а потом на n-грамы от начала слова;
- pattern - позволяет использовать регулярное выражение для определения разделителя;
- path - разбивает путь к файлу на эелементы пути, по слешу.
Самые интересные токенизаторы, это ngram и enge_ngram. Они позволяют разбивать текст на n-граммы, последовательности из определённого количества букв. Оба разбивают текст сначала на слова, а затем эти слова на n-граммы. Но первый создает n-граммы только от начала каждого слова, а второй для всех букв слова. Это довольно удобно, потому что позволяет пользователям вводить для поиска не слово целиком, а только его часть.
5. Настройка токенизатора edge_ngram
Такой токенизатор очень часто используется для автоматического дополнения ввода пользователя и для быстрых подсказок, подобных тем, что показываются при вводе поискового запроса в Google. Вот основные параметры токенизатора edge_ngram, которые нужно задать:
- min_gram - минимальный размер n-граммы;
- max_gram - максимальный размер n-граммы;
- token_chars - символы из которых состоят слова, необходимо для того чтобы текст корректно разбивался на слова, а уже сами слова на n-граммы. Доступны значения: letter, digit, punctuation, symbol, whitespace.
Давайте посмотрим как работает токенизатор edge_ngram:
GET _analyze
{
"tokenizer" : {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit"
]
},
"text" : "В чащах юга жил был цитрус, да но фальшивый экземпляр"
}
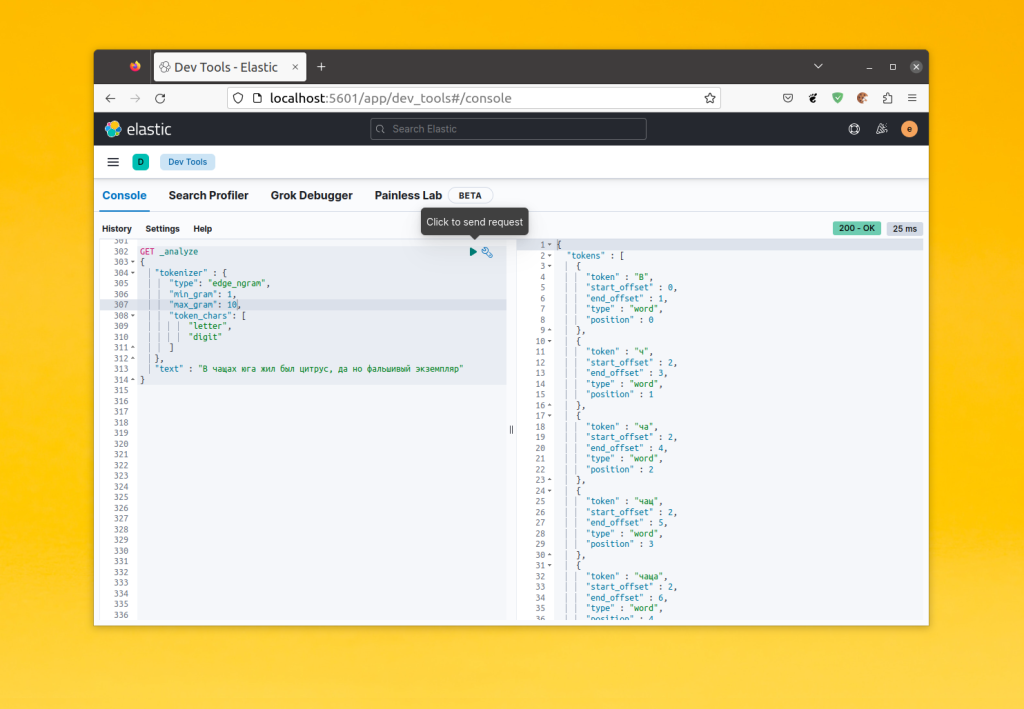
Как видите, слова разбиваются на n-граммы от начала слова, например: ч, ча, чащ, чаща, чащах. Таким образом если пользователь начнет вводить слово в поиск, то ElasticSearch сможет догадаться что он хочет найти. Кроме того, если вы хотите чтобы в ваши слова входили другие символы, можно добавить в массив token_chars тип custom и в поле custom_token_chars прописать нужные символы. Например:
GET _analyze
{
"tokenizer" : {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
},
"text" : "В. чащах_юга- жил был цитрус, да но фальшивый экземпляр"
}
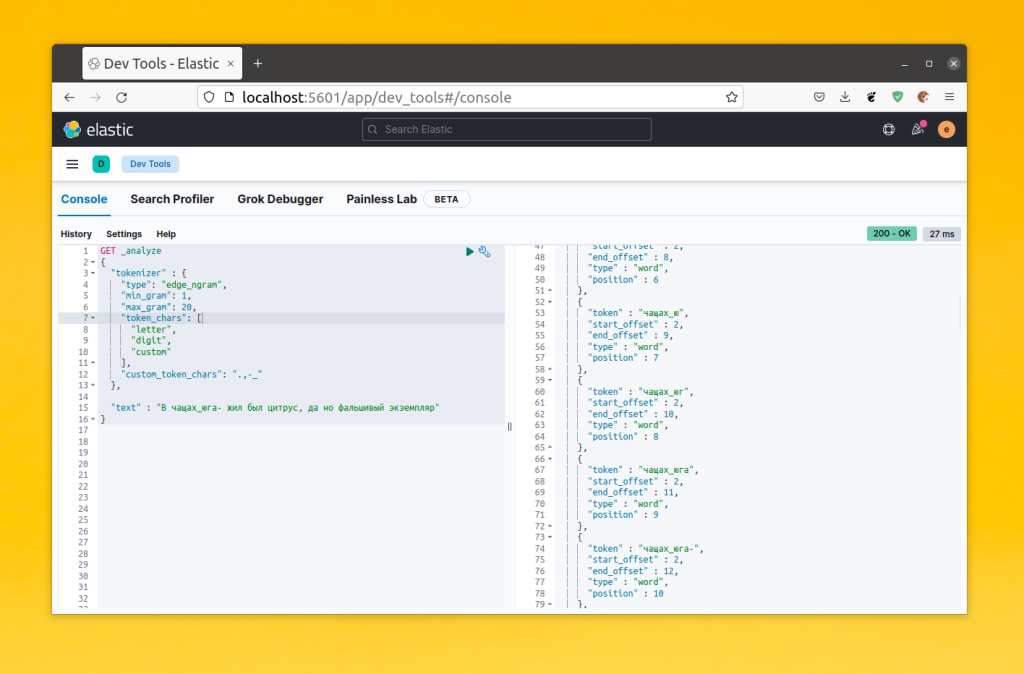
Теперь эти символы находятся в токенах и могут использоваться в поиске. Для того чтобы добавить такой токенизатор в свой анализатор в секции settings -> analysis необходимо создать объект tokenizer и там описать настройки нового токенизатора, после чего добавить его в анализатор. Например:
PUT test_index
{
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
}
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": [
"lowercase"
]
}
}
}
},
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Теперь при поиске можно использовать части слова, например: ч, ча, чащ, чаща. И всё это будет работать. Кроме, того если в слове содержатся символы из ранее заданного списка, то оно тоже будет находится. Например:
GET _search?index=test_index
{
"query": {
"match": {
"title": {
"query": "чащах_юга-",
"operator": "and"
}
}
}
}
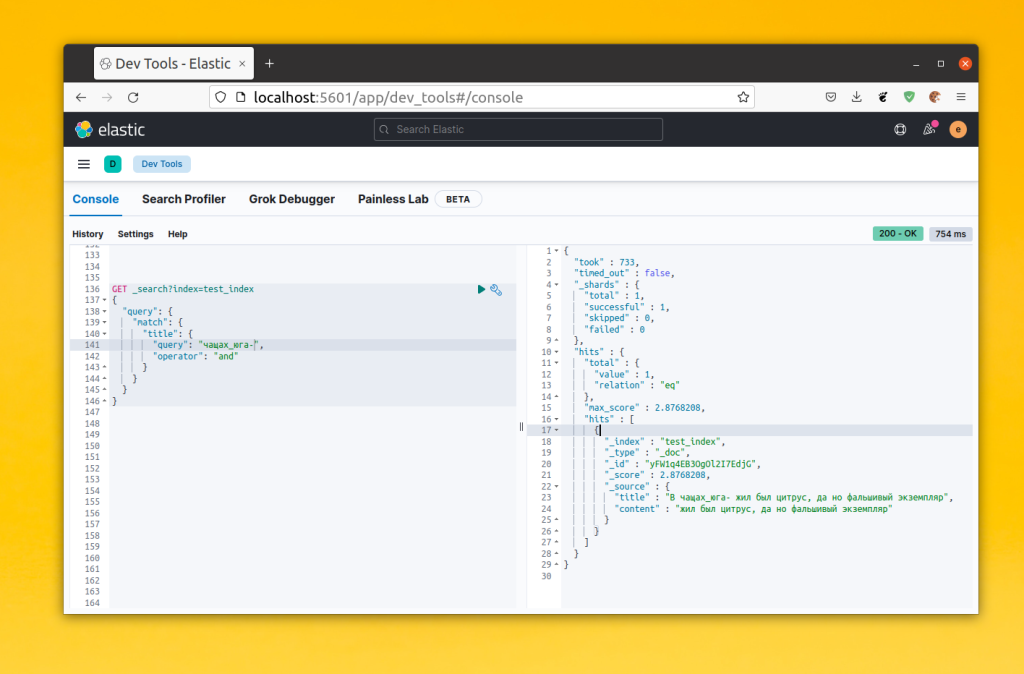
6. Настройка токенизатора ngram
Предыдущий токенизатор довольно интересный, но он имеет свои ограничения. Поисковый запрос должен начинаться обязательно с начала слова в тексте. Если пользователь введет несколько символов из середины слова, то ElasticSearch ничего не найдёт. Если это не желательное поведение, то лучше использовать токенизатор ngram. Он разбивает весь текст на n-граммы независимо от слов.
Параметры тут те же что и у edge_ngram, но, по умолчанию параметр max_ngram может быть больше за min_ngram на единицу. Это не всегда подходит. Для того чтобы это исправить можно воспользоваться настройкой max_ngram_diff на уровне индекса:
PUT another_index
{
"settings": {
"max_ngram_diff": 20
}
}
GET another_index/_analyze
{
"tokenizer" : {
"type": "ngram",
"min_gram": 1,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
},
"text" : "В чащах юга жил был цитрус, да но фальшивый экземпляр"
}
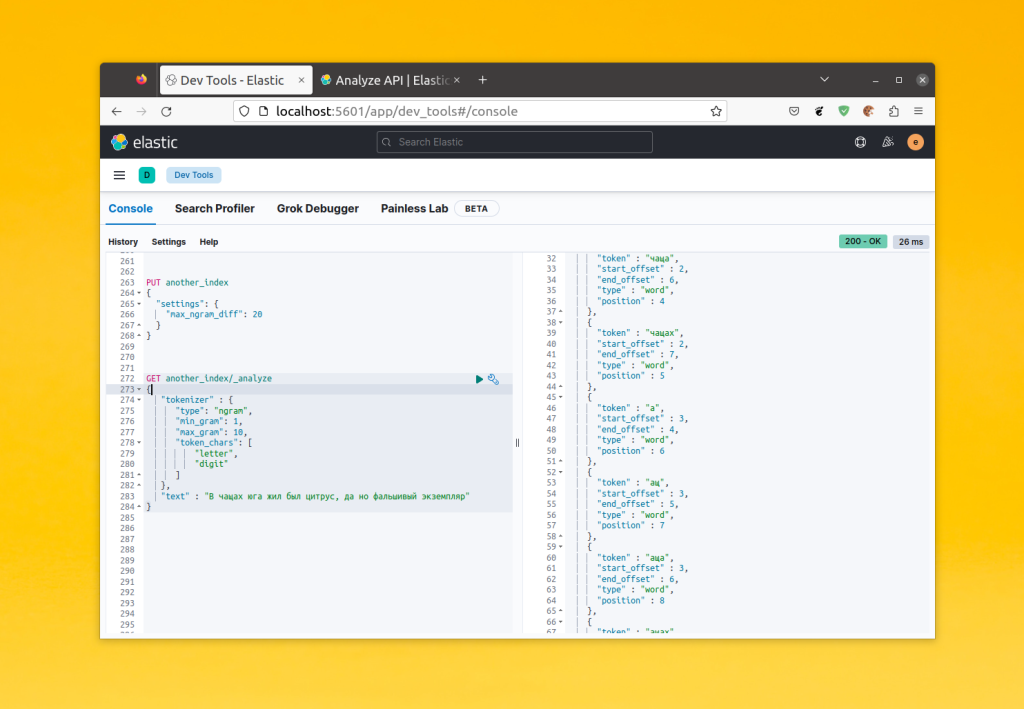
7. Настройка фильтров
Как вы уже видели, с помощью фильтров можно изменять токены. Например, приводить их к нижнему регистру, удалять стоп слова или символы. Если фильтр не требует настройки можно добавить его прямо в анализатор. Если же в фильтре нужно задать определённые параметры, его нужно настраивать также как и токенизатор. Для этого в секции settings -> analysis создайте объект фильтр, и там опишите нужный фильтр. Например, можно добавить поддержку морфологии русского языка в свой анализатор с помощью фильтра stemmer. Это будет выглядеть вот так:
"settings": {
"analysis": {
"filter": {
"russian_stemmer": {
"type": "stemmer",
"language": "russian"
}
}
//.......
}
}
Дальше этот фильтр можно добавить в массив фильтров анализатора. Вы можете посмотреть как будет работать фильтр с помощью API анализа:
GET _analyze
{
"tokenizer" : {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
},
"filter": {
"type": "stemmer",
"language": "russian"
},
"text" : "В чащах_юга- жил был цитрус, да но фальшивый экземпляр"
}
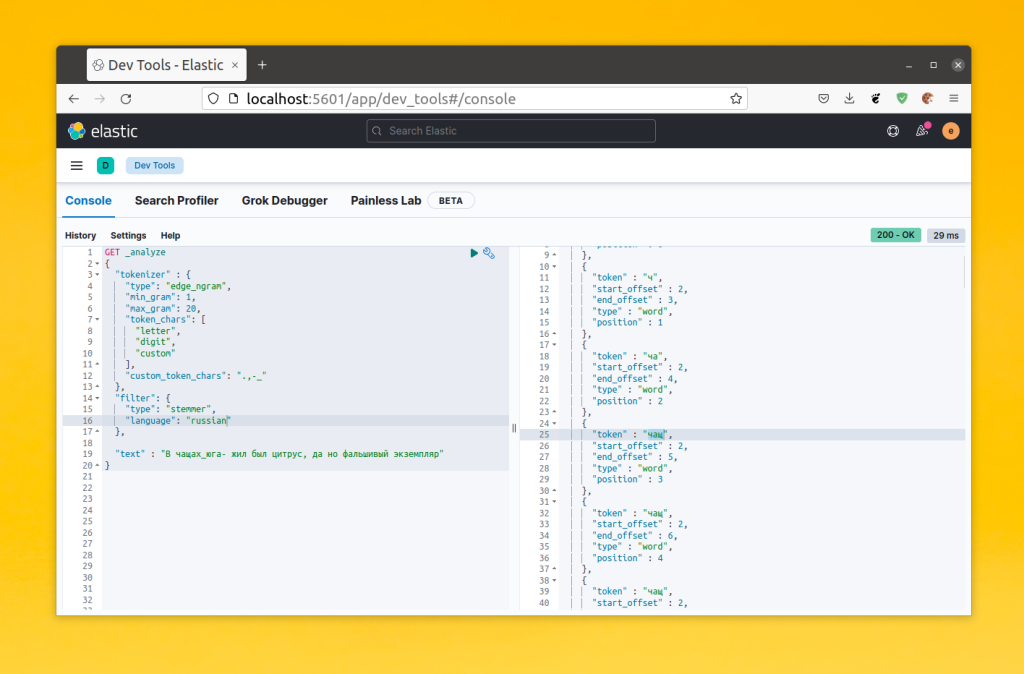
Как видите, здесь все слова, которые были в словаре стиммера были приведены к корневой форме и теперь пользователи будут находить больше релевантных результатов.
8. Синонимы
Часто в поиске возникает необходимость задать синонимы для определённых слов. В ElasticSearch синонимы можно задать на этапе создания индекса с помощью фильтров токенов. Для этого используется фильтр synonym или synonym_graph. Первый работает для обычных синонимов. Для синонимов, которые состоят из нескольких слов надо использовать synonym_graph, но его можно применить только в анализаторе поиска. Давайте рассмотрим пример использования synonym_graph. Синтаксис настройки фильтра выглядит так:
"filter": {
"synonym": {
"type": "synonym_graph",
"synonyms": [ "синоним_1, синоним_2, синоним_3" ]
}
}
Для примера давайте создадим анализатор, который будет использоваться только на этапе поиска и будет поддерживать синонимы для слова чаща:
PUT test_index
{
"settings": {
"analysis": {
"filter": {
"synonym_filter": {
"type": "synonym_graph",
"synonyms": [
"чащах, зарослях, гуще, дебрях, куще"
]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
}
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": [
"lowercase"
]
},
"custom_search_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"synonym_filter"
]
}
}
}
},
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_search_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_search_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
После того как вы создадите этот индекс, можно проверить как работает его анализатор с фильтром синоноимов:
GET test_index/_analyze
{
"analyzer": "custom_search_analyzer",
"text": "В чащах югра жил был цитрус, да но фальшивый экземпляр"
}
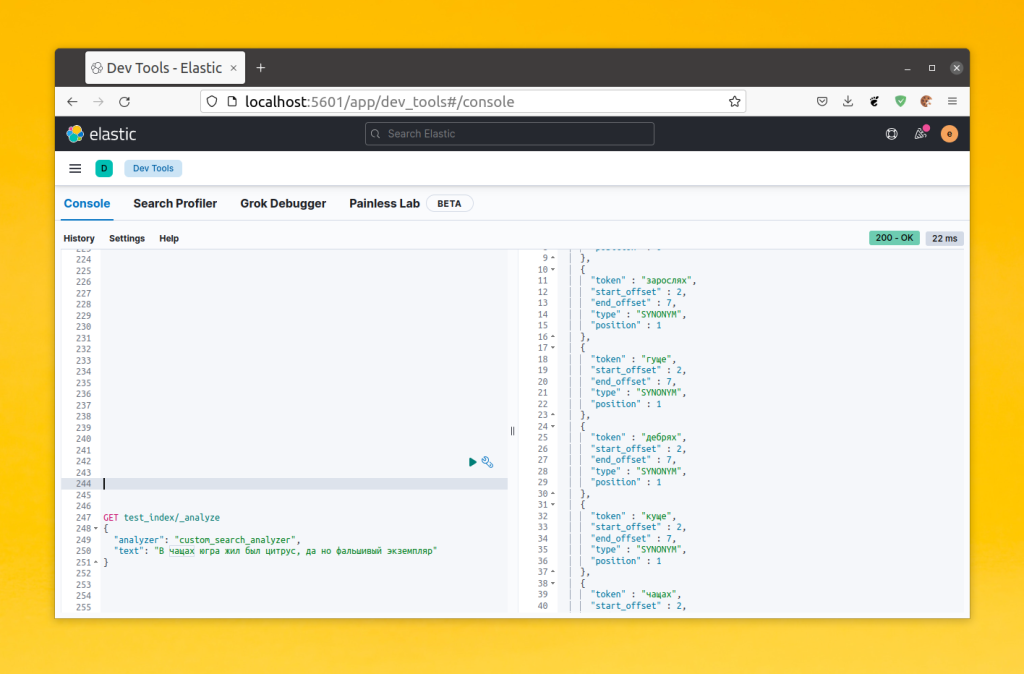
Как видите, теперь для слова, у которого есть синонимы, создаются токены всех синонимов и при поиске в индексе такие слова будут находится по синонимам.
Выводы
В этой статье мы рассмотрели как использовать Elasticsearch для поиска. Если его правильно настроить, то получится довольно мощный поисковый движок, который будет выдавать релевантные результаты для вашего проекта. Как видите, тут есть довольно много интересного и в статье были рассмотрены только основы. Чтобы разобраться во всём более подробно вам нужно обратиться к официальной документации.

Error 451 Unavailable For Legal Reasons