Что такое файловая система? Согласно высказыванию одного из первых мэйнтейнеров Linux и автора популярных книг - Роберта Лава, файловая система - это иерархическое хранилище данных, придерживающиеся определённой структуры.
Однако, это описание одинаково хорошо подходит как для VFAT (Virtual File Allocation Table), так и для Git, Cassandra и других баз данных. Так что же отличает файловую систему? В этой статье мы попытаемся ответить на этот вопрос, а также разобраться что такое виртуальные файловые системы.
Содержание статьи
- Основы файловых систем
- /tmp
- /proc и /sys
- Слежение за VFS
- Файловые системы только для чтения
- Bind и overlay монтирование
- Выводы
Основы файловых систем
Ядро Linux требует, чтобы во всём, что считается файловой системой были реализованы методы open(), read(), и write() для постоянных объектов, у которых есть имена. С точки зрения объективно ориентированного программирования, ядро считает файловую систему абстрактным интерфейсом, в котором определены эти виртуальные функции без реализации. Таким образом реализация файловой системы на уровне ядра называется VFS (Virtual Filesystem).
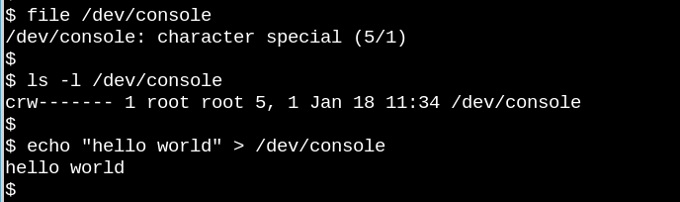
Термин VFS лежит в основе всем известного утверждения о том, что в Unix-подобных системах всё является файлом. Подумайте о том, насколько странно, что приведенная выше последовательность действий с файлом /dev/console работает. На снимке показан интерактивный сеанс Bash в виртуальном терминале TTY. При отправке строки устройству виртуальной консоли, она появляется на виртуальном экране. VFS имеет и другие, даже более странные свойства. Например, в таких файлах можно выполнять поиск.
В таких популярных файловых системах как Ext4, NFS и даже в подсистеме /proc реализованы три основные функции в структуре данных на языке Си, которая называется file_operations. Кроме того, некоторые файловые системы расширяют и переопределяют функции VFS подобным объективно ориентированным способом. Как утверждает Роберт Лав, абстракция VFS позволяет пользователям Linux копировать файлы из других операционных систем или абстрактных объектов, таких как каналы не беспокоясь об их внутреннем формате данных. В пространстве пользователя с помощью системного вызова read() процессы могут копировать содержимое файла в структуры ядра из одной файловой системы, а затем использовать системный вызов write() в другой файловой системе, чтобы записать полученные данные в файл.
Определения функций, относящиеся к VFS находятся в файлах fs/*.c в исходном коде ядра. Подкаталоги fs/ же содержат различные файловые системы. Ядро также содержит объекты, похожие на файловые системы, это cgroups, /dev и tmpfs, которые нужны на раннем этапе загрузки системы и поэтому определены в подкаталоге исходников init/. Обратите внимание, что они не вызывают функции большой тройки из file_operations, зато они могут непосредственно читать и записывать в память.
На схеме ниже наглядно показано, как из пространства пользователя можно получить доступ к большинству файловых систем. На рисунке нет каналов, таймера POSIX и dmesg, но они тоже используют методы из структуры file_operations и работают через VFS:
![]()
Существование VFS способствует повторному использованию кода, поскольку основные методы для работы с файловыми системами не переопределяются в каждой файловой системе. Это широко используемая практика, однако если в таком коде есть ошибки, то от них страдают все реализации, использующие общие методы.
/tmp
Самый простой способ вывести все виртуальные файловые системы, это выполнить такую команду:
mount | grep -v sd | grep -v :/
Она выведет все смонтированные файловые системы, которые не связанны с физическим или сетевым диском. Оной из первых точек монтирования виртуальных файловых систем будет /tmp. Так почему не рекомендуется хранить содержимое /tmp на диске? Потому что файлы из /tmp временные, а постоянные хранилища намного медленнее памяти, где находится tmpfs. Кроме того, физические устройства более подвержены износу от частой записи, в отличие от оперативной памяти. И наконец, файлы в /tmp могут содержать конфиденциальную информацию, поэтому их лучше удалять при каждой перезагрузке.
К сожалению, установщики некоторых дистрибутивов всё ещё размещают /tmp на физическом диске. Но если такое случилось с вашей системой, не расстраивайтесь. Вы можете использовать инструкцию с ArchWiki чтобы исправить проблему. Но не забывайте, что выделенная под tmpfs память больше ни для чего не может быть использована.
/proc и /sys
Помимо /tmp, виртуальные файловые системы, с которыми знакомо большинство пользователей Linux - это /proc и /sys (/dev полагается на общую память и не поддерживает file_operations). Но зачем аж две? Давайте разбираться.
Файловая система procfs предоставляет моментальный снимок состояния ядра и процессов, которые оно контролирует в пространстве пользователя. Кроме того, в /proc ядро делает доступной информацию о прерываниях, виртуальной памяти и планировщике. А ещё в /proc/sys размещены параметры, которые можно настроить из пространства пользователя с помощью команды sysctl. Состояние и статистика по каждому процессу находятся в директориях /proc/<PID>.
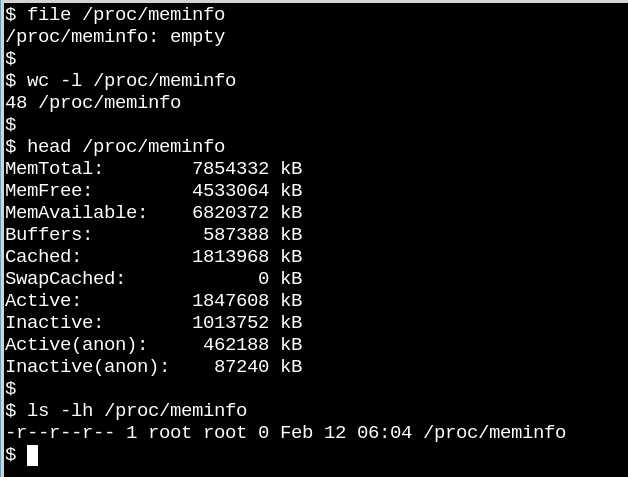
Поведение файлов в /proc показывает, насколько виртуальные файловые системы могут отличаться от, тех, у которых есть файлы на диске. С одной стороны, файл /proc/meminfo содержит информацию, выводимую командой free. Но с другой стороны, он пустой! Как такое может быть. Ситуация напоминает знаменитую статью, написанную физиком Корнельского университета Дэвидом Мермином в 1985 году под названием Есть ли Луна когда никто не смотрит? На самом деле ядро собирает статистику о памяти, когда процесс запрашивает её из /proc. И на самом деле в файлах из /proc ничего нет, когда никто не смотрит. Как сказал Мермин, "Фундаментальная квантовая доктрина состоит в том, что измерение, как правило, не выявляет ранее существовавшее значение измеряемого свойства.
Кажущаяся пустота /proc имеет смысл, поскольку доступная информация динамическая и актуальная на момент получения. Ситуация с файловой системой /sys. Давайте сравним сколько файлов, размером хотя бы один байт, находятся в /proc и /sys:

В procfs такой файл только один - это конфигурация ядра, которую надо генерировать только один раз во время загрузки. С другой стороны в каталоге /sys содержится много файлов большого размера, но большинство из них составляют одну страницу памяти. Обычно файлы из sysfs содержат одно число или строку, в отличие от таблиц информации, например, из /proc/meminfo.
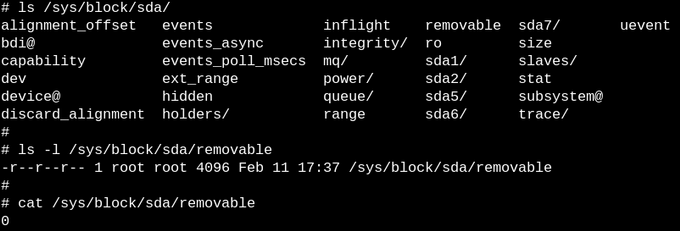
Цель sysfs - предоставить доступ для чтения и записи свойств так называемых объектов kobjects в пользовательском пространстве. Единственная цель kobject - подсчёт ссылок, когда последняя ссылка на kobject будет удалена, система освободит ресурсы, связанные с ним. К тому же, /sys/ составляет основную часть стабильного ABI ядра для пользовательского пространства, которую никто и ни при каких обстоятельствах не может сломать. Но это не значит, что файлы в sysfs статичны. Это бы противоречило подсчёту ссылок.
Стабильность ABI ограничивает то, что может появится в /sys, а не то, что на самом деле есть в любой конкретный момент. Перечисление разрешений на файлы в sysfs дает представление о том, что настраиваемые параметры устройств, модулей и файловых систем можно прочитать и изменить. По логике procfs тоже должна быть частью стабильного ABI ядра, однако в документации об этом ничего не сказано.
Слежение за VFS
Самый простой способ узнать как ядро управляет файлами в sysfs - это посмотреть на это всё в действии. А самый простой способ это сделать на ARM64 или x86_64 - это использование eBPF. eBPF (extended Berkeley Packet Filter) - состоит из виртуальной машины, работающей на уровне ядра, к которой привилегированные пользователи могут обращаться из командной строки. Исходный код ядра показывает читателю как ядро может что-то сделать. Инструменты eBPF показывают как на самом деле всё происходит.
К счастью, начать работу с eBPF довольно просто с помощью инструментов bcc, для которых доступны пакеты в множестве дистрибутивов. Инструменты bcc - это скрипты на Python с небольшими фрагментами кода на Си, а это значит, что любой кто знаком с этим языком может их модифицировать. На данный момент существует около 80 скриптов на Python в bcc, поэтому каждый найдёт то, что ему надо.
Чтобы получить общее представление о работе VFS в работающей системе используйте простые скрипты vfscount и vfsstat, которые покажут, что каждую секунду выполняются десятки вызовов vfs_open() и подобных функций:

В качестве менее общего примера, давайте посмотрим что происходит, когда к работающей системе подключается USB накопитель:
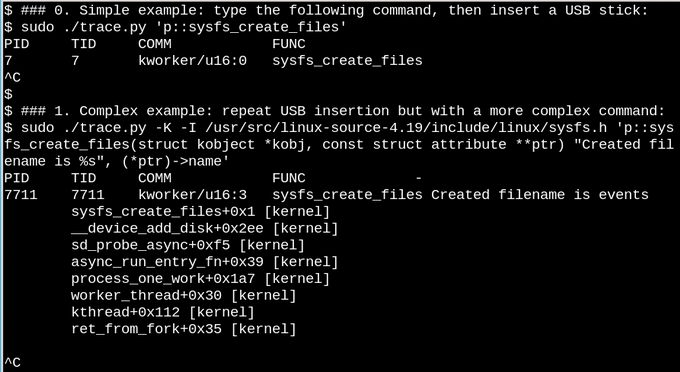
В первом примере на этом снимке скрипт trade.py выводит сообщение всякий раз, когда вызывается функция sysfs_create_files(). Вы можете видеть, что эта функция была вызвана процессом kworker после подключения USB, но какой файл был создан? Следующий пример иллюстрирует полную силу eBPF. Скрипт trade.py выводит трассировку вызовов ядра (опция -K), а также имя файла, созданного функцией sysfs_create_files(). Фрагмент в одинарных кавычках - это строка кода на Си, которую Python скрипт компилирует и выполняет внутри виртуальной машины в ядре. Полную сигнатуру функции sysfs_create_files () надо воспроизвести во втором примере чтобы можно было ссылаться на один из её параметров в функции вывода. Ошибки в этом коде вызовут ошибки компиляции.
Когда USB-накопитель вставлен, появляется трассировка вызовов ядра, показывающая что один из потоков kworker с PID 7711 создал файл с именем events в sysfs. При попытке отслеживать вызов sysfs_remove_files() вы увидите, что извлечение флешки приводит к удалению файла events в соответствии с идеей отслеживания ссылок. Отслеживание sysfs_create_link() во время подключения USB накопителя показывает что создается не менее 48 ссылок.
Зачем же нужен файл events? Используя инструмент cscope можно найти функцию __device_add_disk(), которая вызывает функцию disk_add_events(). А та в свою очередь может записать в файл "media_change" или "eject request". Здесь ядро сообщает в пользовательское пространство о появлении или исчезновении диска. Это намного информативнее, чем просто анализ исходников.
Файловые системы только для чтения
Никто не выключает сервер или компьютер, просто отключив питание. Почему? Потому что примонтированные файловые системы на физических устройствах могут выполнять запись и структуры данных файловой системы могут быть не полностью перенесены на диск. Когда такое происходит, вам придется при следующей загрузке подождать восстановления файловой системы с помощью fsck, а в худшем случае вы даже можете потерять данные.
Тем не менее, вы наверное слышали, что многие встраиваемые устройства, такие как маршрутизаторы, термостаты и даже автомобили работают под Linux. У многих из этих устройств нет пользовательского интерфейса и их невозможно корректно выключить. Представьте автомобиль, основной компьютер которого полностью отключается, когда разряжается батарея. Как тогда быстро включить компьютер, когда двигатель снова заработает и батарея восстановит заряд? Ответ прост. IoT устройства используют корневую систему в режиме только для чтения или коротко ro-rootfs.
Такой подход даёт несколько преимуществ, которые менее очевидны чем неповреждаемость. Одна из них - вирусы не могут выполнять запись в /user или /lib если ни один процесс Linux не может выполнять туда запись. Во вторых это обеспечивает удобную поддержку удалённых устройств, поскольку они имеют такую же файловую систему как и тестовые образцы. Самое важное обстоятельство такого подхода - разработчикам приходится решать на этапе проектирования какие компоненты системы должны быть неизменяемыми. Работа с ro-rootfs иногда может быть очень сложной, но преимущества компенсируют недостатки.
Создания таких файловых систем требует дополнительных усилий от разработчиков и здесь снова на помощь приходит VFS. Linux требует, чтобы файлы в /var были доступны для записи, кроме того, множество приложений будут пытаться создавать скрытые файлы в домашней папке. Решением для файлов конфигурации в домашнем каталоге может быть их предварительное создание. В каталог /var можно монтировать отдельный раздел, доступный для записи, тогда как корень будет все ещё доступен только для чтения. Другая же альтернатива - использование bind и overlay монтирования.
Bind и overlay монтирование
Лучше всего про монтирование файловых систем и про bind монтирование в частности можно узнать выполнив такую команду:
man mount
Bind и overlay монтирование позволяет разработчикам встраиваемых систем и системным администраторам создавать файловую систему, доступную по определённому пути, а потом делать её доступной приложениям по совсем другому пути. Для встраиваемых систем подразумевается что можно хранить файлы из /var на устройстве доступном только для чтения, но наложить на /var tmpfs, так чтобы приложения могли туда писать если им это надо. При перезагрузке все изменения в /var будут утеряны. Overlay монтирование позволяет объединить tmpfs и обычную файловую систему так, чтобы в ней можно было изменять файлы, а bind монтирование позволяет сделать доступными для записи пустые папки с tmpfs в ro-rootfs. Хотя overlayfs - это отдельная файловая система, bind монтирование выполняется с помощью VFS.
Исходя из всего этого, не удивительно, что контейнеры Linux активно используют overlay и bind монтирование. Давайте посмотрим что происходит, когда мы запускаем контейнер с помощью systemd-nspawn. Будем использовать инструмент mountsnoop из набора bcc:

Осталось посмотреть что произошло:
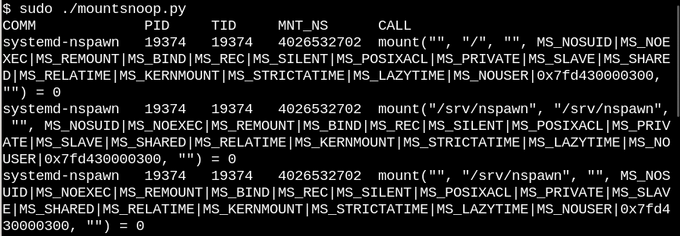
Здесь systemd-nspawn размещает нужные файлы из procfs и sysfs хоста в контейнер. Здесь помимо флага MS_BIND, означающего bind-монтирование есть флаги, которые настраивают связь при изменениях файлов процессами контейнера или хоста. Например, файловая система может автоматически отображать изменения в контейнере или скрывать их.
Выводы
Понимание внутреннего устройства Linux может показаться невыполнимой задачей, поскольку само ядро содержит огромный объем кода и это не считая приложений пространства пользователя и библиотеки glibc. Один из способов достичь прогресса - прочитать исходный код одной из подсистем ядра, обращая внимание на системные вызовы, которые используются пространством пользователя, а также на основные внутренние интерфейсы ядра, вроде структуры file_operations.
Структура file_operations - это то, что делает концепцию "Всё есть файл" работающей, поэтому изучение информации о ней особенно интересно. Исходные файлы ядра в каталоге fs/ представляют собой реализацию виртуальных файловых систем, которые представляют из себя слой прокладки для взаимодействия между физическими устройствами и популярными файловыми системами. Bind и overlay монтирование - это магия VFS, которая делает возможным использование Linux на IoT устройствах и контейнеры. Инструменты eBPF вместе с изучением исходного кода ядра, делают исследование ядра проще чем когда либо.


Здравствуйте!
Object-oriented - объектно-ориетнированный, а не объективно ориентированный, всё-таки.
Объект, а не объективный.
Очень познавательно, спасибо!
К вопросу о монтировании /tmp в оперативную память:
Хотя разработчики Debian/Ubuntu и отказались применять его по умолчанию, опасаясь некоторых редких программ, имеющих склонность помещать в /tmp слишком большие объемы данных, что создавало бы угрозу переполнения пространства ОЗУ, тем не менее заготовили юнит systemd для пользователей, заинтересованных в данной функции. Таким образом, чтобы заставить эти дистибутивы монтировать /tmp в память, достаточно скопировать названную заготовку в видимый для systemd каталог и активировать ее, на что потребуется всего две команды:
sudo cp -v /usr/share/systemd/tmp.mount /etc/systemd/system/
sudo systemctl enable tmp.mount
https://wiki.debian.org/SSDOptimization#Reduction_of_SSD_write_frequency_via_RAMDISK